We recently got rid of prerender because of the promise from the last article from google saying the same thing [1]. It didn't work.
1: http://googlewebmastercentral.blogspot.com/2014/05/understan...
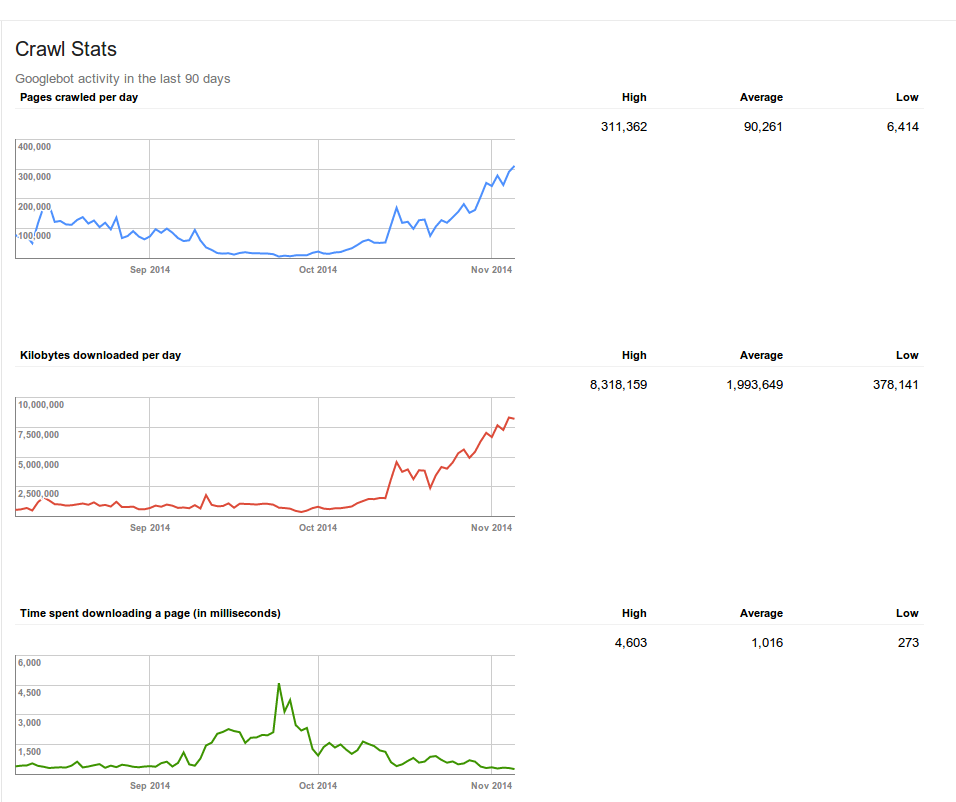
[1] This image is from 2014, when Google previously announced they were crawling JavaScript websites, showing our customer's switch to an AngularJS app in September. Google basically stopped crawling their website when Google was required to execute the JavaScript. Once that customer implemented Prerender.io in October, everything went back to normal.
Another customer recently (June 2015) did a test for their housing website. They tested the use of Prerender.io on a portion of their site against Google rendering the JS of another portion of their site. Here are the results they sent to me:
Suburb A was prerendered and Google asked for 4,827 page impressions over 9 days Suburb B was not prerendered and Google asked for 188 page impressions over 9 days
We've actually talked to Google some about this issue to see if they could improve their crawl speed for JavaScript websites since we believe it's a good thing for Google to be able to crawl JavaScript websites correctly, but it looks like any website with a large number of pages still needs to be sceptical about getting all of their pages into Google's index correctly.
1: https://s3.amazonaws.com/prerender-static/gwt_crawl_stats.pn...
Historically Google has been using some fork of Chrome 10 when indexing. I'm unsure what impact that is having on the reliability of app rendering, but I also trust the Google search team has done reasonable checks ensuring common sites and frameworks render correctly.
I strongly suggest using a sitemap for JS rendered sites, based on my own experience.
Then again, I really like react+redux+koa (r3k) for client-server rendering.... Hoping to do something more serious with it in the next few months at work.
Can we forget about any new competitors in search engine land now? Not only do you have to match Google in relevance you'll actually have to implement your own BrowserBot just to download the pages.
Google does malware detection. Not on every crawl, but a certain percentage of crawls. At my old social network site, they detected malware that must have come from ad/tracking networks because those pages had no UGC. This suggests they were using Windows virtual machines (among others) and very likely using browsers other than a heavily modified curl / wget and a headless Chrome.
They started crawling the JavaScript-rendered version of the web and AJAX schemes that use URL shebangs. This was explicit acknowledgement that they were running JavaScript and did advanced DOM parsing.
They have always told people that cloaking (either to Google crawler IP blocks, user-agent, or by other means) content is a violation and they actively punished it. This suggests they do content detection and likely execute JavaScript to detect if extra scripts change the content of the page for clients that don't appear to be Googlebot.
They have long had measures in place to detect invisible text (eg. white text on white background) or hidden text (where HTML elements are styled over other HTML elements). This suggests both CSS rendering and JS rendering.
I think you're making a number of wild assumptions there. You can scan and detect malware without running Windows; and there's a whole gulf of different technologies between running desktop browsers and running a modified version of curl.
With regards to your browser point, normally I'd probably suggest that Google would be running node and making use of their own V8 Javascript engine to headlessly render the pages. However Google have the resources to build something much more bespoke so I think it would be foolish of me to make blind assumptions given how little I actually know about their internal technology.
No, this actually suggests it's not doing either. Both invisible and hidden text the way you've described it would be implemented with a CSS style. Not using that style would mean the text would appear as normal. I understand you probably meant that the JS was injecting the text in, which is fully possible, but that's neither hidden nor invisible text.
I'm working on a couple of projects in vertical search, and it is quite exciting. Sure, I'm building tech that Google had in 2005, but we are surprised with the results. We achieve search relevance simply by curating the sites we crawl (still in the thousands in some cases).
Trying to get away from the "W3Schools effect" [0], where outdated, terribly presented information or downright spammy pages are locked in the top results of Google by virtue of being around for so long, or by gaming search keywords [1].
I'm not sure where I sit on this, developers who want to be noticed by other engines will continue to focus on SEO, but how many engineers care about SEO that isn't Google?
Of course Google competitors must work hard. I don't see why that's a bad thing. It's not like Bing or Yandex are going to disappear in the foreseeable future.
Biaudu is one SE that doesn't crawl JS well from my research.
It was always just a little white noise in the past, but when suddenly a couple hundred thousand pages permanently redirect... it was interesting.
I really hope this works, lots of JS libraries expect things like viewport and window size information, I wonder how Google is achieving that.
I bet they'd also skip on all the FB like buttons and other common social media elements that don't impact the content.
Just plug in common screen parameters (e.g. 1920x1080, 1366x768, ...) and analyze it as if it were the result you'd get by default with Chrome on such a screen, I would imagine.
The work could be broken up in any number of ways... from my own testing, and experience with others testing. Content crawls/recrawls from JS data tends to lag a couple days behind initial scan... having an updating sitemap xml resource is a good idea for "new" content if you're doing JS based content.. also, rescans will still lag well behind the general non-js content scans...
Was it ever alive? I never found a decent browser XSL-FO renderer, there were some that seemed kind of proof-of-concept-ish (the only decent XSL-FO rendering I ever encountered was intended for print-like media, mostly PDF, rather than for browsing.)
1 - https://medium.com/@devNoise/seo-fail-figuring-out-why-i-can...
http://searchengineland.com/google-may-discontinue-ajax-craw... March 5th: Gary said you may see a blog post at the Google Webmaster Blog as soon as next week announcing the decommissioning of these guidelines.
Pure speculation but interesting... The timing may have something to do with Wix, a Google Domains partner, who is having difficulty with their customer sites being indexed. The support thread shows a lot of talk around "we are following Google's Ajax guidelines so this must be a problem with Google". John Mueller is active in that thread so it's not out of the realm of possibility someone was asked to make a stronger public statement. http://searchengineland.com/google-working-on-fixing-problem...
I'm guessing they've likely cut this time in half through a combination of additional resources, and performance improvements. Wondering if they'd be willing to push this out as something better than PhantomJS... probably not as it's a pretty big competative advantage.
I know MS has been doing JS rendering for a few years, they show up in analytics traffic (big time if you change your routing scheme on a site with lots of routes, will throw off your numbers).
<meta name="fragment" content="!">
Does this announcement mean I can remove the <meta> tag and stop using prerender.io now?
http://searchengineland.com/google-working-on-fixing-problem...
{kind=link}