I know there are lots of file descriptors not usable with epoll or rather async i/o in general and that sucks (e.g. regular files).
For networking, I find epoll/sockets nicer to work with than Windows' IOCP, because with IOCP you need to keep your buffers around until the kernel deems your operation complete. I think you have 3 options:
1) Design the whole application to manage buffers like IOCP likes (this propagates to client code because now e.g. they need to have their ring buffer reference-counted).
2) You handle it transparently in the socket wrapper code by using an intermediate buffer and expose a simple read()/write() interface which doesn't require the user to keep a buffer around when they don't want the socket anymore.
3) You handle it by synchronously waiting for I/O to be cancelled after using CancelIo. This sounds risky with potential to lock up the application for an unknown amount of time. It's also non-trivial because in that time IOCP will give you completion results for unrelated I/Os which you will need to buffer and process later.
On the other hand, with Linux such issues don't exist by design, because data is only ever copied in read/write calls which return immediately (in non-blocking mode).
In Linux, you don't, and userspace and kernelspace both end up doing unnecessary copying, and it means with shared buffers, something might poll and not-block, but actually block by the time you get around to using the buffer.
This is annoying, and it generally means you need more than two system calls on average for every IO operation in performance servers.
As a rule, you can generally detect "design faults" by the number of competing and overlapping designs (select, poll, epoll, kevent, /dev/poll, aio, sigio, etc, etc, etc). I personally would have preferred a more fleshed out SIGIO model, but we got what we got...
One specific fault of epoll (compared to near-relatives) is that the epoll_data_t is very small. In Kqueue you can store both the file descriptor with activity (ident) as well as a few bytes of user data. As a result, people use a heap pointer which causes an extra stall to memory. Memory is so slow...
On Linux if a socket is set to non-blocking it will not block. I don't really understand your point with shared buffers. You wouldn't typically share a TCP socket since that would result in unpredictable splitting/joining of data.
> In Linux, you don't, and userspace and kernelspace both end up doing unnecessary copying
I'm not so sure the Linux design where copies are done in syscalls must be inherently less efficient. I'm pretty sure with either design, you generally need at least one memcpy - for RX, from the in-kernel RX buffers to the user memory, and for TX, from user memory to the in-kernel TX buffers. I think getting rid of either copy is extremely hard and would need extremely smart hardware, especially the RX copy (because the Ethernet hardware would need to analyze the packet and figure out where the final destination of the data is!). Getting rid of TX copy might be easier but still hard because it'd need complex DMA support on the Ethernet card that could access potentially unaligned memory addresses. On the other hand, I also don't think you need more than one copy, if you design the network stack with that in mind.
> you need more than two system calls on average for every IO operation in performance servers.
True but it's not obvious that this is a performance bottleneck. Consider that a single epoll wait can return many ready sockets. I think theoretically it would hurt latency rather than throughput.
> As a rule, you can generally detect "design faults" by the number of competing and overlapping designs.
On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing. On Windows, it's much more complicated - see this list of different methods to use sockets (my own answer): http://stackoverflow.com/questions/11830839/when-using-iocp-...
> One specific fault of epoll (compared to near-relatives) is that the epoll_data_t is very small.
Pretty much universally when you're dealing with a socket, you have some nontrivial amount of data associated with it that you will need to access when it's ready for I/O, typically a struct which at least holds the fd number. Naturally you put a pointer to such a struct into the epoll_data_t. I don't see how one could do it more efficiently outside of very specialized cases.
Windows overlapped IO can map the user buffer directly to the network hardware, which means that in some situations there will be zero copies on outbound traffic.
> especially the RX copy I also don't think you need more than one copy, if you design the network stack with that in mind.
When the interrupt occurs, the network driver is notified that the DMA hardware has written bytes into memory. On Windows, it can map those pages directly onto the virtual addresses where the user is expecting it. This is zero copies, and just involves updating the page tables.
This works because on Windows, the user space said when data comes in, fill this buffer, but on Linux the user space is still waiting on epoll/kevent/poll/select() -- it has only told the kernel what files it is interested in activity on, and hasn't yet told the kernel where to deposit the next chunk of data. That means the network driver has to copy that data onto some other place, or the DMA hardware will rewrite it on the next interrupt!
If you want to see what this looks like, I note that FreeBSD went to a lot of trouble to implement this trick using the UNIX file API[0]
> On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing.
Linux also supports SIGIO[1], and there are a number of aio[2] implementations for Linux.
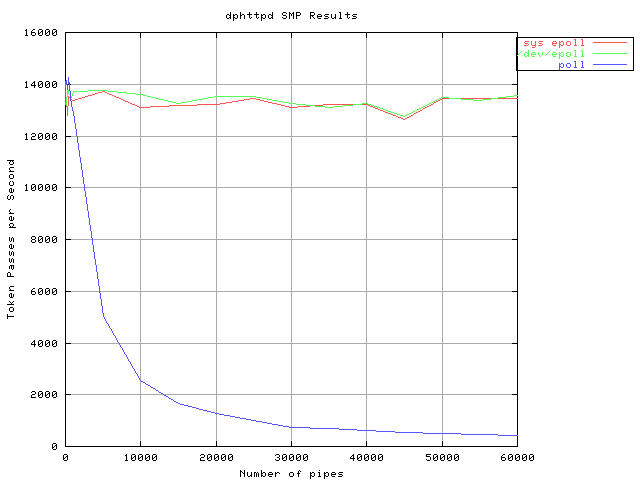
epoll is not the same as poll: Copying data in and out of the kernel costs a lot, as can be seen by any comparison of the two, e.g. [3]
Also worth noting: Felix observes[4] SIGIO is as fast as epoll.
> I don't see how one could do it more efficiently
Dereferencing the pointer causes the CPU to stall right after the kernel has transferred control back into user space, while the memory hardware fetches the data at the pointer. This is a silly waste of time and of precious resources, considering the process is going to need the file descriptor and it's user data in order to schedule the IO operation on the file descriptor.
In fact, on Linux I get more than a full percent improvement out of putting the file descriptor there, instead of the pointer, and using a static array of objects aligned for cache sharing.
For more on this subject, you should see "what every programmer should know about memory"[4].
[0]: http://people.freebsd.org/~ken/zero_copy/
[1]: http://davmac.org/davpage/linux/async-io.html#sigio
[2]: http://lse.sourceforge.net/io/aio.html
[3]: http://lse.sourceforge.net/epoll/dph-smp.png
Solaris event ports are good, but they're still ultimately backed by a readiness-oriented I/O model, and can't be used for asynchronous file I/O.
https://blogs.oracle.com/dap/entry/libevent_and_solaris_even...
https://blogs.oracle.com/praks/entry/file_events_notificatio...
And Solaris, (unlike Linux historically at least), supports async I/O on both files and sockets. Linux (historically) only supported it for sockets. I have no idea if Linux generally supports async I/O for files at this point.
This isn't a terrible recap of async file I/O issues on contemporary operating systems: http://blog.libtorrent.org/2012/10/asynchronous-disk-io/
The difference between Windows Overlapped I/O and POSIX AIO is that on Windows it's a black box, so people can pretend it's magical. Whereas on Linux there hasn't been interest (AFAIK) to merge patches that provide a kernel-side pool of threads for doing I/O, and the decades-long debates have spilled out onto the streets. If you view userspace code as somehow inelegant or fundamentally slow, then of course all the blackbox Windows API and kernel components look appealing. What has held Linux back regarding AIO is that Linux (and Unix people in general) have historically preferred to keep as much in userspace as possible.
This is why NT has syscalls taking 11 parameters. In the Unix world you don't design _kernel_ APIs that way, or any APIs, generally. In the Unix world you prefer simple APIs that compose well. read/write/poll compose much better than overlapped I/O, though which model is most elegant and useful in practice is highly context-dependent. As an example, just think how you'd abstract overlapped I/O in your favorite programming language. C# exposes overlapped I/O directly in the language, but doing so required committing to very specific constructs in the language.
As for performance, both Linux and FreeBSD support zero-copy into and out over userspace buffers. The missing piece is special kernel scheduling hints (e.g. like Apple's Grand Central Dispatch) to optimize the number of threads dedicated per-process and globally to I/O thread pools. But at least not too long ago the Linux kernel was much more efficient at handling thousands of threads than Windows, so it wasn't really an issue. That's another thing Linux prefers--optimizing the heck out of simpler interfaces (e.g. fork), rather than creating 11-argument kernel syscalls. IOW words, make the operation fast in all or most cases so you don't need more complex interfaces.
My understanding is that Solaris event ports were intended to offer equivalent functionality to Windows' I/O completion ports, so this should not be surprising.
Solaris also has its own native async I/O API in addition to supporting POSIX async.
http://www.visualcomplexity.com/vc/project.cfm?id=392
Are you saying the Windows flow looks like spaghetti only because the software tested software (Apache) wasn't designed for Windows?
It's hard to evaluate this in any way more than "yeah that's a cute spaghetti diagram". If I wanted to drag Linux through the mud visually I'd depict how much time every socket I/O op spends in vfs/fsync stuff. (i.e. you can depict anything to make your point)
{kind=link}