I always end up spending a fair amount of time using tools like:
And of course stackoverflow.
Very useful when code reviewing other people's regular expressions.
Links :
https://www.microsoft.com/en-us/research/publication/symboli...
https://www.microsoft.com/en-us/download/details.aspx?id=523...
It now seems to be Open Source (MIT):
I am toying the idea of writing a little game where player A thinks of a regular expression, and player B tries to guess. If B guesses right, they win. If B guesses wrong, A has to provide a false positive and a false negative (if they exist), and B gets to guess again.
Can you think of ways to automate the roles of A and/or B?
A classic algorithm for inferring regular expressions was given by Angluin: https://people.eecs.berkeley.edu/~dawnsong/teaching/s10/pape...
(This isn't quite the same setup as you're thinking of but there are a ton of variations on the basic idea)
Automation of regular expression generation, it seems easy : use RE fragments and aggregate them, or walk the type hierarchy of the RE AST and generate them randomly.
B needs to guess A's RE so we need to generate examples of strings belonging to it to gives hints : this is exactly the use case of AutomataDotNet.
Also if B guess a RE that is equivalent to A's RE it seems unfair to not attribute a win, so we need to tell if 2 RE belong to the same equivalence class. AutomataDotNet does have a AreEquivalent method.
You can automate the generation of false positive and a false negative with the method Minus to creates an automaton that accepts A-B or B-A and generate an example.
But I guess if it's meant for an audience of folks not very familiar with regexes it's difficult enough as it is.
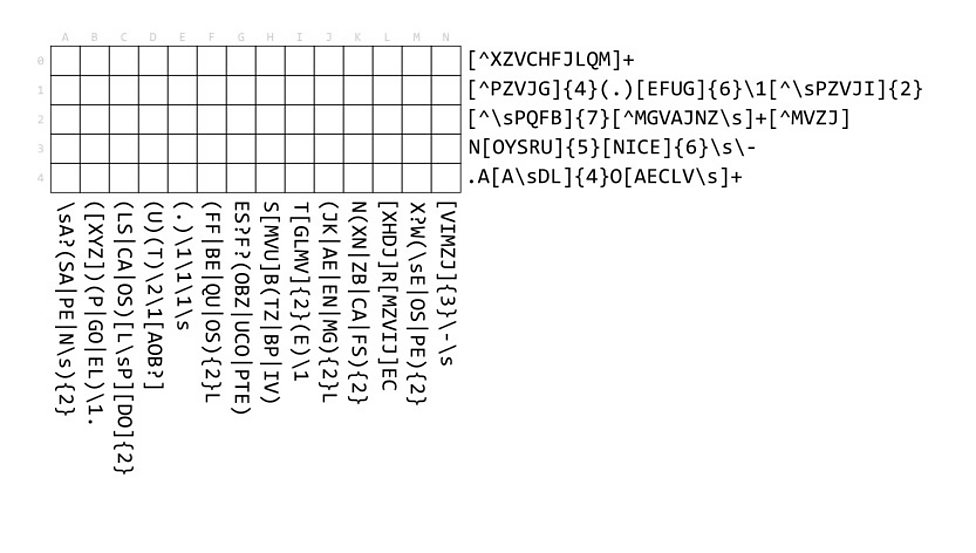
[1] https://www.ncsc.gov.uk/news/take-our-regex-crossword-challe...
https://devjoe.appspot.com/huntindex/puzzle/mit2013601
PDF: http://web.mit.edu/puzzle/www/2013/coinheist.com/rubik/a_reg...
The puzzles generally don't tell you how to extract the answer, but the idea is you know it when you see it.
Some implementations: https://github.com/ekmett/ersatz/tree/master/examples/regexp... https://gist.github.com/LeventErkok/4942496
For example, you can split each one of these regexes up into smaller ones based on positioning. Now some of them are simply "match any of the following characters" which can be combined together with set intersections (and something similar with "none of these characters).
The published solution says H0 should be "S".
Guess nobody tested it.
I suppose the two main benefits are
(a) neither the writer nor the reader has to remember which punctuation characters are meta-characters (you just have to remember that it's always a literal if it's escaped), and
(b) in implementations like PHP's which try to replicate the Perl-style 'delimited' syntax (e.g., /foo/), it prevents characters in the pattern from conflicting with the delimiters.
Maybe there's some other advantage but i can't think of what.
The designer is local so if they no longer stock it you could look online...but it's better to get it from the shop if you can.
{kind=link}
{kind=link}
{kind=link}