Waymo handling city traffic with LIDAR.[2] They show the scan lines and some of the path planning. Busy city streets, lots of obstacles.
Tesla self-driving demo, April 2019.[3] They show their display which puts pictures of cars and trucks on screen. No difficult obstacles are encountered. Recorded in the Palo Alto hills and on I-280 on a very quiet day. The only time it does anything at all hard is when it has to make a left turn from I-280 south onto Page Mill, where the through traffic does not stop. [3] Look at the display. Where's the cross traffic info?
Tesla's 2016 self driving video [5] is now known to have been made by trying over and over until they got a successful run with no human intervention. The 2019 demo looks similar. Although Tesla said they would, they never actually let reporters ride in the cars in full self driving mode.
[1] http://gmauthority.com/blog/2019/06/how-cruise-self-driving-...
[2] https://www.youtube.com/watch?v=B8R148hFxPw
[3] https://www.youtube.com/watch?v=nfIelJYOygY
Tesla's display does not render all of the data that the computer knows about.
Additionally this article is assuming the camera based solution for Tesla will be single-camera. Last I checked the actual solution is going to be stereo vision of multiple cameras (think one on each side of windshield) and using ML to combine that data. The Model 3 does not have that capability though because its three cameras are center mounted.
This is the main takeaway. Unsurprising but interesting nonetheless. I'm working in the field and it confirms my experience.
However they have a big bias that need to be pointed out:
[...] we must be able to annotate this data at extremely high accuracy levels or the perception system’s performance will begin to regress.
Since Scale has a suite of data labeling products built for AV developers, [...]
Garbage in, garbage out; yes annotation quality matters. But they're neglecting very promising approaches that allow to leverage non-annotated datasets (typically standard rgb images) to train models, for example self-supervised learning from video. A great demonstration of the usefulness of self-supervision is monocular depth estimation: taking consecutive frames (2D images) we can estimate per pixel depth and camera ego-motion by training to wrap previous frames into future ones. The result is a model capable of predicting depth on individual 2D frames. See this paper [1][2] for example.
By using this kind of approach, we can lower the need for precisely annotated data.
[1] https://arxiv.org/abs/1904.04998
[2] more readable on mobile: https://www.arxiv-vanity.com/papers/1904.04998/
Edit: typo
Yeah, I find it odd that they're bringing up Elon's statement about LiDAR, but then completely ignore that they spoke about creating 3D models based on video. They even showed [0] how good of a 3d model they could create based on dat from their cameras. So they could just as well annotate in 3D.
An interesting intermediate case between a pure video system and a lidar is a structured light sensor like the Kinect. In those you project a pattern of features onto an object in infrared. Doesn't work so well in sunlight but be interested in learning if someone had ever tried to use that approach with ego motion.
Aren't those the types of walls, barriers, truck behinds that tesla's keep ramming into? :S
Then you'd get all that sweet, sweet depth data that lidar provides but cheaper and at a much higher resolution.
> One approach that has been discussed recently is to create a pointcloud using stereo cameras (similar to how our eyes use parallax to judge distance). So far this hasn’t proved to be a great alternative since you would need unrealistically high-resolution cameras to measure objects at any significant distance.
Doing some very rough math, assuming a pair of 4K cameras with 50 degree FOV on opposite sides of the vehicle (for maximum stereo separation) and assuming you could perfectly align the pixels from both cameras, it seems you could theoretically measure depth with a precision of +/-75 cm for an object 70 meters away (a typical braking distance at highway speeds.) In practice, I imagine most of the difficulty is in matching up the pixels from both cameras precisely enough.
Humans do lot more than just identifying an image or doing 3d reconstruction. We have context about the roads, we constantly predict the movement of other cars, we do know how to react based on the situation and most importantly we are not fooled by simple image occlusions. Essentially we have a gigantic correlation engine that takes decision based on comprehending different things happening on the road.
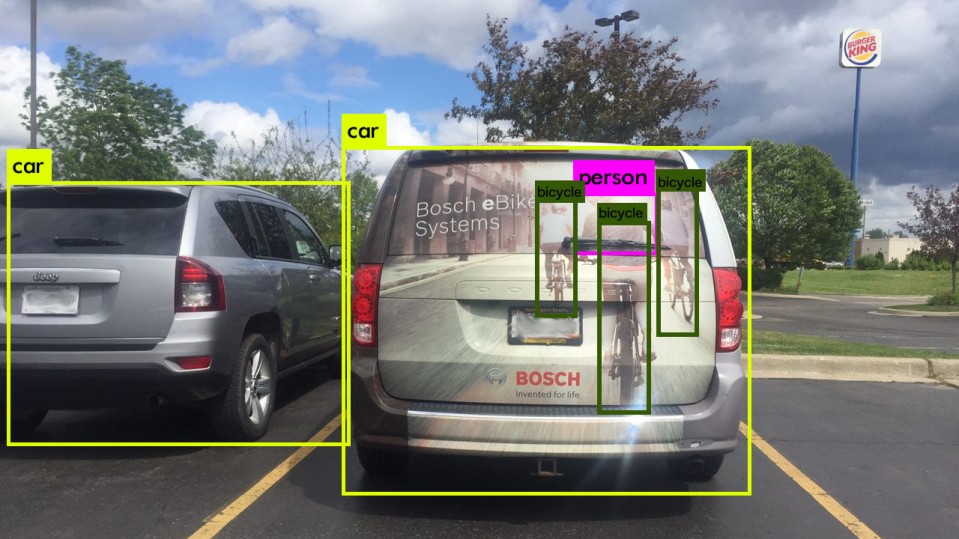
The AI algorithms we teach does not work in the same way as we do. They overly depend on the identifying the image. Lidar provides another signal to the system. It provides redundancy and allows the system to take the right decision. Take the above linked image for an example.
We may not need a lidar once the technology matures but at this stage it is a pretty important redundant system.
That's not relevant when discussing which technology to use to build the 3d models. Everything you said is accurate until the last few sentences. Lidar provide the same information (line of sight depth) as stereo cameras, just in a different way. The person you're responding to is talking about depth from stereo, not cognition.
This is incorrect, the amount of parallax you need to get the same kind of accurate depth using camera is infeasible. Velodynes other common lidar now gets you points accurate at 150m+. Cameras can't do that, and if you use nets to guess you'll still make mistakes.
> The person you're responding to is talking about depth from stereo, not cognition.
You miss the point; saying human 3D reconstruction works because of sensors without world context is naive. The response was trying to capture that; human perception systems utilize context / background knowledge extensively.
I had always assumed that the first few years of infancy was effectively a period of training a neural net (the brain) against a continuous series of images (everything seen).
Also provides a reliable source of data, if humans have a LiDAR in their system then we would use it to improve our decisions.
I don’t see why we should limit the AV.
Easy examples of this are optical illusions, ghosts, and ufos. There is also "selective attention tests" where a majority of people miss glaringly obvious events right in front of them, when they're focusing on something else. Regular people also tend to bump into things, spill things, and trip, even when going 3 miles an hour (walking speed).
So it seems that a truly accurate 3D representations of the world are not necessary, at least for driving. Perhaps it's the resolution? Looking at the samples in the article, they are just terribly fuzzy, with a narrow field of view. If I had to drive and only see the world through that kind of view, I don't think I would be doing very well.
We learn objects representations by interacting with them over years in a multi modal fashion. Take for example a simple drinking glass: we know its material properties (it is transparent, solid, can hold liquids), its typical position (stay on a tabletop, upright with the open side on top), its usage (grab it with a hand and bring to mouth)...
We also make heavy use of the time dimension, as over a few seconds we see the same objects from different view points and possibly in different states.
Only after learning what a glass is can we easily recover its properties on a still 2D image.
So at least for learning (might be skippable at inference), it makes a lot of sense to me to have more than 2D still images.
All I'm saying is that even with stereo inputs, we're doing more than computing depth from the baseline between left/right images. Close one eye and you can still estimate relative objects positions, because you learned that roads are mostly planar and cars don't float but stand on the road. You know what the expected size of a car is compared to, say, a human, and if the car is visually smaller than the human, it must be more far away.
Lidar _also_ doesn't know what the glass feels like.
Yes I agree with you, lidar and most current vision sensors also suffer from this.
> Two cameras of any resolution spaced a regular distance apart should be able to build a better parallax 3D model than any one camera alone.
This is true if the platform isn't moving.
If you have the time dimension and you have good knowledge of motion between frames (difficult), you can use the two views as a virtual stereo pair. This is called monocular visual/inertial-SLAM. You can supplement with GPS, 2D lidar, odometry and IMU to probabalistically fuse everything together. There have been some nice results published over the years.
But in general yes, you'll always be better off if you have a proper stereo pair with a camera either side of the car.
The idea that the human brain has a "near perfect" 3D representation of one's surroundings seems inaccurate to me. There's a difference between near perfection and good enough that people don't often get hurt, when all of their surroundings are deliberately constructed to limit exposure to danger.
And it is indeed an impressive and heroic piece of work when you can fix sensor problems with clever filtering, or fix mechanical problems with clever control algorithms. But when designing new equipment or deciding a path to fix a bad design, you never want to hamstring yourself from the start with poor quality input data and output actuators. That approach only leads to pain.
Once you have lots of experience with a particular design - dozens of similar machines running successfully in production for years - then you can start looking for ways to be clever and improve performance over the default or save a little money.
I understand Elon's desire to get lots of data. But there will be a much greater chance of success if it starts with Lidar + cameras, and a decade down the road you can work on camera-only controls and compare what they calculated and would have done to what the Lidar measured and the car actually responded. Only when these are sufficiently close should you phase out the Lidar.
Remember, you're comparing bad input data going to the best neural net known in the universe (the human brain) with millenia of evolution and decades of training data to sensor inputs to brand new programming. Help out the computer with better input data.
The other thing is that we, ideally, want a computer to drive a car better than a human can. There's a lot to be gained from having precise rather than approximate notions or other objects' distances and speeds in terms of driving both safely and efficiently. Now, Tesla has also got that Radar which when fused with visual data will help somewhat but I'm not sure how far that can get them.
but it takes at least 10 years to train.
But most of the time we are not building a 3d map from points. we are building it from object inference.
There are many advantages that we have over machines:
o The eye seens much beter in the dark o It has a massive dynamic range, allowing us to see both light and dark things o it moves to where the threat is o if it's occluded it can move to get a better image o it has a massive database of objects in context o each object has a mass, dimension, speed and location it should be seen in
None of those are 3d maps, they are all inference, where one can derrive the threat/advantage based on history.
We can't make machines do that yet.
you are correct that two cameras allows for better 3d pointcloud making in some situations. but a moving single camera is better than a static multiview camera.
however even then the 3d map isn't all that great, and has a massive latency compared to lidar.
I have thought about this many times and often wondered why when closing one eye I am still able to function.
Sense then I have thought strongly that having depth perception is used for training some other part of our brain, and then only used to increase accuracy of our perception of reality.
Further proof of this is TV. Even on varying sized screens humans tend to do well figuring out the actual size of things displayed.
Some of them translate trivially to photos/TV/etc, like convergent lines or texture gradient. Some of them are surprisingly physical, like feedback from your eyes about vergence or focal distance.
Stereo is highly effective up close, say within 10 meters (yards). And it works faster than many modes. It's absolutely fantastic for catching things out of the air. Given our intraocular distance, it's basically garbage past, I dunno, 30m or something? (obviously it degrades smoothly across distance)
I've heard more than one academic (evolutionary cognitive psychologists, etc) speculate that the single biggest evolutionary advantage of having two eyes is to have a spare in the event of damage. That might well be just whimsy and exaggeration, but I think it puts a helpful alternate perspective on it (pun!).
One reason why you're still able to function is that you don't rely on your sense of depth that much these days. i.e. You don't need to gage where a spear or arrow will land. Even in a car, you are effectively on a one dimensional track and only have to decided to go left or right.
If you only had one eye, then in situations where there is lots of pressure to perceive depth I think you'd have to move your head around a lot.
Which makes me wonder, which human activities demand the best depth perception?
If a person is standing next to a bush then we roughly know their height since we know the range of sizes that a bush could grow to. Likewise the size of someone like Thanos from Avengers would look odd in a documentary but because its a superhero movie we assume that's normal.
Self driving cars to my knowledge do none of this.
Driving back home with 1 eye was scary even though I was going much slower. It is possible to drive with 1 eye, but much much harder than with 2 eyes.
https://en.wikipedia.org/wiki/Depth_perception#Theories_of_e...
https://en.wikipedia.org/wiki/Depth_perception
This seems like a bit of a double-edged sword. On the one hand, it means there's more than one way to achieve a 3D model of the world with cameras. On the other hand, it means that if what machines can do with cameras is going to match what we humans can do with our eyes, they will need to either advance along 18 different fronts or take some of those cues further than we can.
Otherwise we'll just have to figure out how to build autonomous vehicles with the technology we have, which is pretty crappy in comparison to biology in a lot of ways still.
With cameras and computer vision there's no way to prove it. There is always a chance that it will glitch out for a second and kill someone.
We don’t know yet what the acceptance rate is for autonomous accidents - but I can guarantee it’s not the rational value of 1:1 or “as safe as humans”. They’ll need to do a lot better.
If what you say is true then a future where robot cars kill 500,000 per year and 20,000 in the USA would be considered acceptable.
Yet we know this is absolutely not the case, no society will ever stand for such a massive death toll due to robot usage. Are there any industries today where robots are allowed to kill so many?
We accept deaths because of human failing as there is no other way, the alternative is no cars.
So for us to hand over the reins to robots they need to be near perfect, think the accident rates of the airline industry as the only acceptable goal.
This is ridiculous.
I am sitting in front of a monitor right now. Please explain how I can perfectly determine the depth of it even though I can't see behind it ? I can move my ahead all around it to capture hundreds of different viewpoints but a car can't do that.
The point Musk and others are making though is that the lidar on the market today has poor performance in weather. The cameras will struggle to a degree in weather as well, so not having good annotations when your dev car is driving though rain is exactly the time when you need the ground-truth to be as clean as possible.
They are saying that lidar enhances the perception system to get more accurate dimensions and rotations of objects to a greater distance.
this means that you can predict far better, allowing you, for example, to drive at night full speed.
Weather affects visual systems as well. The "ooo rain kills lidar" is noise at best. Visual cameras are crap at night.
There is a reason that the radar augmented depth perception demo is in bright light, no rain. Because it almost certainly doesn't work as well at night, and will probably need a separate model.
Mitigated somewhat with headlights
Infra-red cameras work, but RGB not so much (well not in the <$400 per CCD price point)
There’s also one instance where it gives lidar the advantage because it’s mounted on top of the car and can see over signs. What?!
But that's really beside the point because the world is not static and any system attempting self-driving will need to take that into account.
Using parallax measurements which is what Tesla says they are doing, you can dramatically increase the estimates of depth measurements by comparing multiple frames of 2D images.
Also, just a reminder that Tesla is also using radar in conjunction with the cameras.
I am not expert in this field: how tracking actually works with a time dimension? These must be some sort of "state" carried over frame-by-frame? What is the "size" of this state? Objects just do not disappear and reappear for certain frames? This latter effect you can often see on many automatic labeling demos you find on GitHub.
GM is shipping millions of cars annually, with the same FSD capability as any Tesla on the road. That is: zero FSD capability.
Eg, it seems like they are taking the "figure it out later" approach, but they limited what they can work with to just camera information. Which to me is a shame. I'd like to see Tesla's model with lots of inputs.
Then again, I don't ship these cars, so I'm probably being ignorant :)
I think when cars are 95 or 99% autonomous they will be sold with human remote control so there will be centers where manufacturers have hundreds of remote drives ready to intervene and handle the last 5% or 1% of situations. Ther race to AV profitability will be won by the manufacturer with the smallest army of backup drivers.
[1] https://www.theverge.com/2019/8/15/20805994/ups-self-driving...
This is basically just an ad for Scale and Scale's services, which include... drawing bounding boxes around objects in still frames.
And the title is inflammatory. Nobody who understands the discussion is talking only about camera versus lidar. It’s more about camera+radar versus camera+radar+lidar, and other comparisons between other hybrid or standalone sensor combinations. It’s not as simple as one versus the other... surprised we still have to point this out to them.
And if we also have cars share their sensor data?
Would that speed things up in terms of achieving full autonomy?
Investment wise it wouldn't be impossible since roads are already expensive to build.
And in the end, your car has to be able to come to a safe stop and avoid dangers no matter the situation. Even with no other cars around or communication interrupted. To reliably achieve this will probably get you most of the way to "real" self driving, with humans/remote operators manually taking care of the few remaining cases.
But he also admits that presently Google is ahead of everyone in the race for level 5, but raises the question of whether they can ever do it economically enough to make money on it?
https://www.youtube.com/watch?v=iwcYp-XT7UI 2 hours!
Money quote is when Lex tells him, ""Some non-zero part of your brain has a madman in it"
I'd argue that is true of many of the greatest inventors of our time.
I also listened to the podcast. George made it sound like the Lidar wasn’t being used for much. It augments the maps to help determine more precise location?
Edit: misread the parent comment
> sponsored by the Tesla shorts
i.e. people who are betting against Tesla.
This is reasoning is exactly backwards. If your perception system can forecast accurately, it simply must not be weak or inaccurate.
The question here is, what is important information for a system to perceive to make accurate forecasts? Lidar might help a bit... But we know it simply is not required.
Musk may be right or wrong, but this article is a non-sequitur.
Except people don't drive reliably in inclement weather at all, so you don't really want that as the gold standard.
Training a car to be as good as average people driving in the rain/snow would be horrible.
So what was Musk's point ?
https://news.ycombinator.com/item?id=20677720
https://news.ycombinator.com/item?id=20680495
https://news.ycombinator.com/item?id=20683288
I submitted a blog post the other day that got 150 comments - I only noticed afterwards it had already been submitted 6 or 7 times before in the months preceding, each without attracting any comments.
{kind=link}