This adaptor connects react-admin with Hasura: https://github.com/Steams/ra-data-hasura-graphql
"PostgREST serves a fully RESTful API from any existing PostgreSQL database. It provides a cleaner, more standards-compliant, faster API than you are likely to write from scratch."
Disclaimer: my startup. We will do a public launch soon, but the restful component of Supabase is a postgrest instance, and we are wrapping it with some libraries to make it a bit quicker to get started.
I've made my own contribution here too, with a tool to join and analyse data in various databases and file formats (JSON, CSV, Excel) using plain SQL, OctoSQL: https://github.com/cube2222/octosql
Everything old is new again!
Database Backed Web Sites:
The Thinking Person's Guide to Web Publishing
Philip Greenspun - 1997
I'm working on a desktop application which has feature to let users query data across a bunch of different data sources, like csv, excel, and some others. The way I've implemented this is by first scanning all applicable files and populating a SQLite database with all the data from these files, a table per file essentially, and then allowing users to execute queries against the database. The database is updated whenever any of these files are changed on disk, but any writes to the database are not persisted back into the files on disk, so it's really a one-way kind of flow. This was all implemented mostly as a proof-of-concept, but it's been massively useful so we're probably going to expand on it this year, perhaps by allowing bi-directional workflows.
Even if the use cases and approach is different, it's nice and validating to see other projects with similar thoughts and ideas. Again, thanks for sharing!
I think I've seen an open source project with the approach described by you too.
However, I think philosophically we differ in that one of our goals is to push down as much work as possible to the underlying databases and our next big upcoming milestone is streaming (Kafka, possibly database change streams).
But yes, it's great that a kind of ecosystem is forming around those ideas!
[2] http://downloads.nakedobjects.net/resources/Pawson%20thesis....
Tools like these are a viable, low-code (to use a hyped-up term) alternative to creating full-blown back-ends with all the boilerplate code that comes with them. Often these back-ends add little more than a REST API or a simple CRUD interface on top of an SQL database.
RDBMS on the other hand are immensely powerful tools that unfortunately more often than are used for little more than simple data storage.
I wonder if there aren't projects aimed a building just an administration GUI based on SQL introspection mixed with simple configuration files. Just point at a db, and there you go.
Side note : what is the current state of codegen based on api and model specifications ? I feel like 90% of most projects could be automatically generated just based on that.
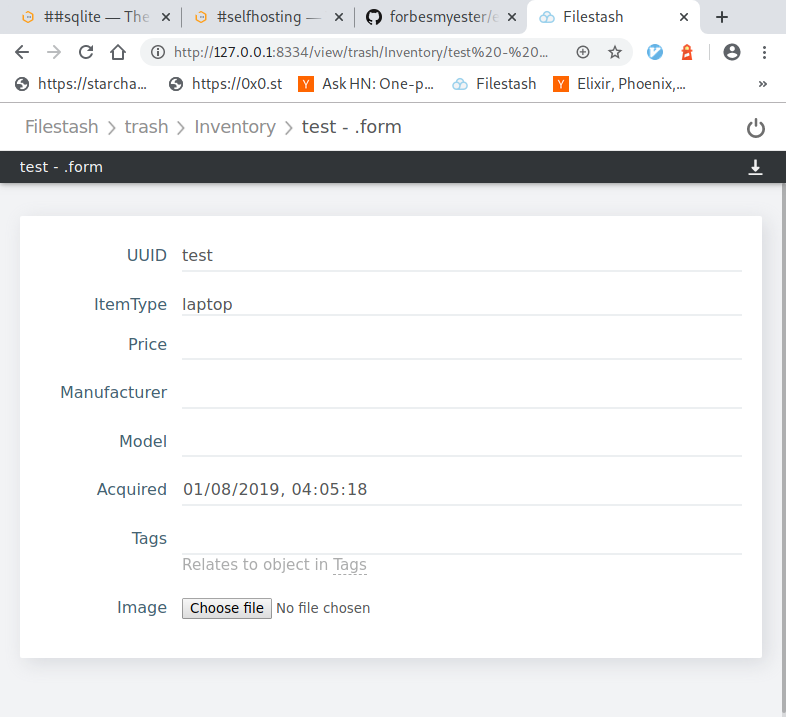
I built exactly this. The idea was to make databases look and feel like a file manager where databases are shown as folder, tables as subfolders and rows are shown as files that once open shows a fully editable form that look like this: https://archive.kerjean.me/public/2020/screenshot_20200117_2... It understands foreign keys and create relevant links to easily navigate through. The entire code is there: https://github.com/mickael-kerjean/filestash
As an advice from a marketing POV : i wouldn't start by explaining that it lets you navigate ftp servers using file abstraction. This is very confusing, because most people already access ftp servers using tools like filezilla clients that do exactly that.
The db -> file browser is a very interesting idea that i think should stand on its own (even if the underlying tech is similar).
I thought that was the whole point of e.g. LibreOffice Base and the like? (including Paradox, Access, etc.) So you built a web-based clone?
But beyond pure data access you'll want features like access rights (SQL servers will offer that to a point), validations, and data/context specific visualizations.
It's not just from the SQL, but we use Sequel (Ruby ORM) to introspect the DB as a starting point, coupled with a plugin to Sequel that lets us annotate the models to provide more precise information that our Sinatra based API introspects to return JSON data to our React frontend that drives how the UI is presented. This extends to e.g. declaring which fields are most useful for users to search for relations that should be linked via foreign keys, for example (e.g. users are linked to by id, but when linking a user from another record, they are searchable by name and e-mail). As much as practical we auto-generation validations etc. from the database schema as well.
I think doing this by SQL alone would be quite painful unless you sacrifice usability, because a typical database schema has too little information on how users think about the data.
E.g. we dialled back on using Postgres enum types because they're annoying to update and deal with if you frequently update the allowed values - but you need relatively little extra config to be able to generate very full-featured interfaces, and you can make most of that extra information entirely declarative. Foreign keys is another issue, as described above - a normal database schema just tells you how things are linked together, not how users would like to see it. E.g. knowing a comment was written by user 42 is much less useful than knowing it was written by bob@example.com; to allow user-friendly linking etc. you'll want more information. We refer to our additional layer of information about the structure of our data as our meta schema.
You certainly could put the parts that don't fit perfectly in your database schema in your database anyway as regular data, and to some extent we do - e.g. the meta information that we augment our Sequel model classes with can be overridden by rows in a table.
But the main reason we've not fully embraced that vs. annotating the model classes in code is that it makes version control painful, and if you update it with migrations it's really not saving that much vs. just putting it in the model classes (this might be different if you have other applications accessing the database and the database in effect needs to be a versioned API in itself accessible by multiple consumers, but in this case all the database access happens via the API exported from the model classes).
One of the things I added is that you could add column formatting in the field names, so a $c would turn it into a currency field, there was one to turn it into boolean checkbox, etc.:
SELECT o.amount, p.price [price$c], p.price * o.amount [total$c]
FROM orders o
JOIN products p
It's a nice feature/idea but I'm torn between implementing it and also allowing you to do it in SQL...
I agree that concat('$', table.amount) as amount should be right aligned, but mine would leave it left aligned (as it became a string).
When I visited a specific page on my site (password protected) I had a bit of Go code that would read all the the files, execute all the (read-only) SQL statements and then dump them into an HTML template that created a table for each one.
Made it dead simple to keep track of some simple metrics like daily sign ups, number of users currently on the site, churn, etc.
Hopefully I can just reach for this next time and not write my own hacky tool :)
We use it to get more insight in our data. It does not allow a user to enter anything.
Basically my app only uses a list of queries. To allow that any selected field is clickable, the result field should be like 'report|name|field,field' so the app knows this is a special link (report) refering to another defined query ('name') and should be passed some values (record specific, here 'field,field').
I tried to clone it and run it locally, but it doesn't run. Tried with both yarn and npm.
> node-sass src/index.scss > public/index.css
sh: 1: node-sass: not found
npm ERR! file sh
npm ERR! code ELIFECYCLE
npm ERR! errno ENOENTAlmost every business software is a select/insert/update. If you can do it over a view, or you have a trigger on insert/update/delete you are able to have a customer facing product with minimal manual operation.
That's simply how SQL deals with 1:n and n:m relations.
from my experience very good for simple logic but once it's is complicated you hate yourself.
I quit my job recently to work on a similar idea.
https://boomsql.com. Still working on a landing page and MVP
It might be the instructions for install a bit off but I've tested on MacOS and Ubuntu (both BASH)... Which method is your install? If it's Docker Compose ( https://github.com/forbesmyester/esqlate#docker-compose-meth... ) it has a BASH line there in the README that does the checkout for you.
[ ! -d "esqlate-server" ] && git clone git@github.com:forbesmyester/esqlate-server.git esqlate-server
This tells me that (a) it is a common problem, and (b) it is not solved well. I'm guilty too: I manage a large MySQL DB and the admin panels are essentially CRUD UI rendered from the schema. The alt solutions I've clicked on here try to add more functionality, but it seems that's where things break, because every solution is different beyond the 1st-order CRUD UI. This seems to indicate there is no generic solution beyond that?
MS Access is totally unscalable and due to it's proprietary licence I can't recommend it to anyone... but it was super freaking easy to stich together a graphical UI usable by non expert users.
I'm a SQL/GIS/Dev based on PostgreSQL/PostGis and I would totally harass my boss to buy such a solution if it were to exist. I have no time to learn latest front-end flavor so being able to quickly deploy any customizable AND simple GUI between my SQL illiterate colleagues an our database would by priceless!
If such solution does exist please have a laugh at me for being ignorant and I would really appreciate if you could send some links to that product!
Hell, I miss Paradox. In DOS. There was a direct relationship between the tables and the UI so you got CRUD as a side effect.
I built several real application using it, but the best was a true "enterprise" application used across three facilities. The "backend" was a Netware file system and the key to making it scale was to cache necessary data locally and batch writes to shared tables. Contention had to be avoided, not because Paradox couldn't multiplex readers and writers, but because the performance was so poor.
It was still spinning when I moved on. Have no idea how long they maintained it, but I'll bet whatever they replaced it with cost an order of magnitude more. It was a part of every dollar of revenue that outfit earned employing ~1000 people.
Let's just laugh at each other and call it even. :)
We use it against both GraphQL and MySQL and a few other services.
{kind=link}