- The expansion of pclntab in Go 1.2 dramatically improved startup time and reduced memory footprint, by letting the OS demand-page this critical table that is used any time a stack must be walked (in particular, during garbage collection). See https://golang.org/s/go12symtab for details.
- We (the Go team) did not “recompress” pclntab in Go 1.15. We did not remove pclntab in Go 1.16. Nor do we have plans to do either. Consequently, we never claimed “pclntab has been reduced to zero”, which is presented in the article as if a direct quote.
- If the 73% of the binary diagnosed as “not useful” were really not useful, a reasonable demonstration would be to delete it from the binary and see the binary still run. It clearly would not.
- The big table seems to claim that a 40 MB Go 1.8 binary has grown to a 289 MB Go 1.16 binary. That’s certainly not the case. More is changing from line to line in that table than the Go version.
Overall, the claim of “dark bytes” or “non-useful bytes” strikes me as similar to the claims of “junk DNA”. They’re not dark or non-useful. It turns out that having the necessary metadata for garbage collection and reflection in a statically-compiled language takes up a significant amount of space, which we’ve worked over time at reducing. But the dynamic possibilities in reflection and interface assertions mean that fewer bytes can be dropped than you’d hope. We track binary size work in https://golang.org/issue/6853.
An unfortunate article.
$ for i in $(seq 3 16); do
curl -sLo go1.$i.tgz https://golang.org/dl/go1.$i.linux-amd64.tar.gz
tar xzf go1.$i.tgz go/bin/gofmt
size=$(ls -l go/bin/gofmt | awk '{print $5}')
strip go/bin/gofmt
size2=$(ls -l go/bin/gofmt | awk '{print $5}')
echo go1.$i $size $size2
done
go1.3 3496520 2528664
go1.4² 14398336 13139184
go1.5 3937888 2765696
go1.6 3894568 2725376
go1.7 3036195 1913704
go1.8 3481554 2326760
go1.9 3257829 2190792
go1.10 3477807 2166536
go1.11 3369391 2441288
go1.12 3513529 2506632
go1.13 3543823 2552632
go1.14 3587746 2561208
go1.15 3501176 2432248
go1.16 3448663 2443736
$
At the moment, it looks like Go 1.17 binaries will get a bit smaller thanks to the new register ABI making executable code smaller (and faster).
¹ Well, not completely. The gofmt code itself was changing from release to release, but not much. Most of the binary is the libraries and runtime, though, so it's still accurate for trends.
² Turns out we shipped the go 1.4 gofmt binary built with the race detector enabled! Oops.
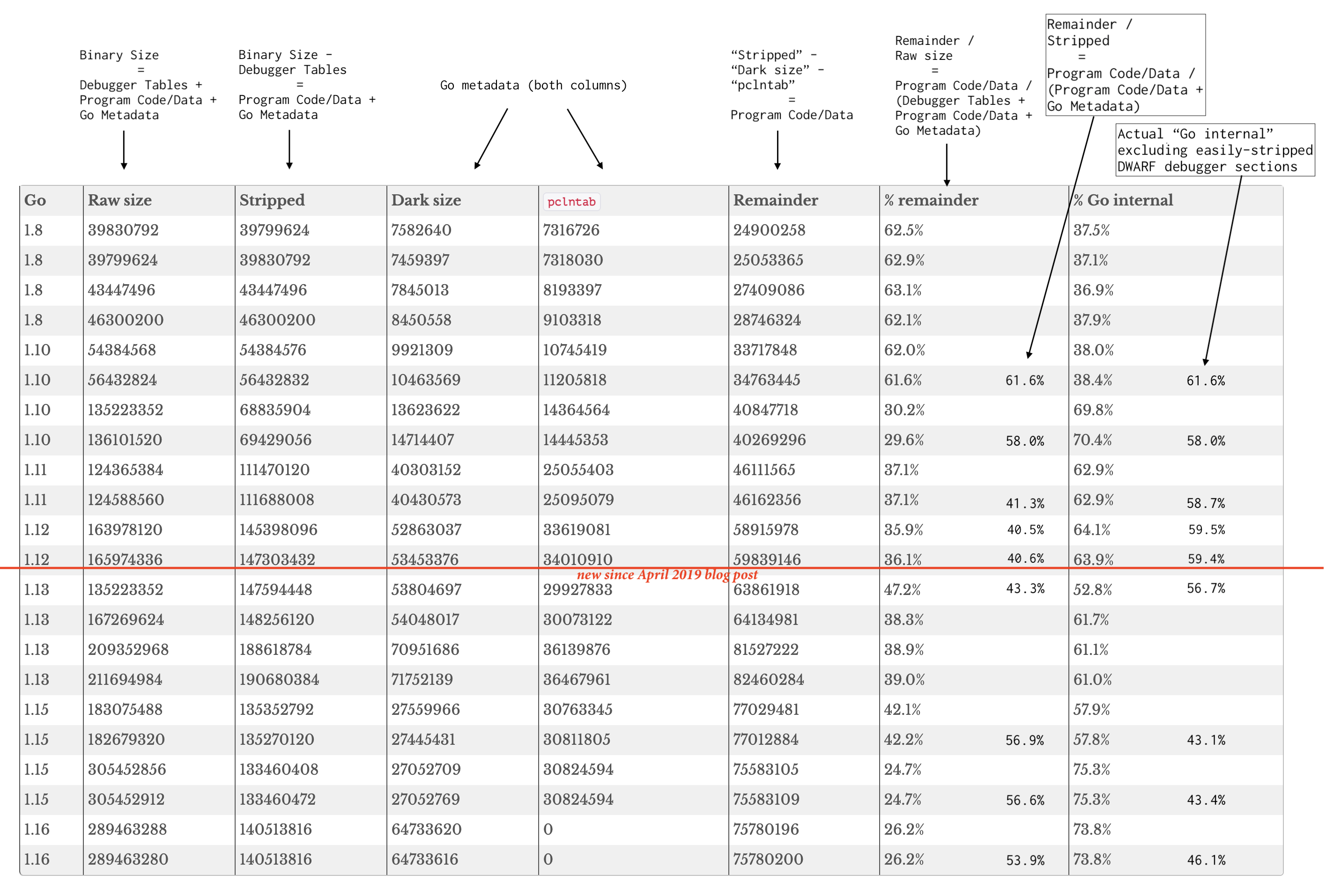
But still, the sum of all the bytes advertised in symbol tables for the non-DWARF data does not sum up to the stripped size. What's the remainder about?
I am reminded of how early versions of MSWord were embedding pages of heap space in save files that were not relevant to the document being saved, just because it made the saving algorithm simpler. For all we know, the go linker could be embedding random data.
I do know, and it is not.
To all the people reading this as a literal accusation instead of hyperbole: plase consider that this reading is only possible under the same bad faith that you're attributing to knz42.
> Every time, 70% of a couple hundred megabytes are copied around for no good reason and someone needs to pay ingress/egress networking costs for these file copies.
That 70% includes the ELF/DWARF metadata that is easily removed from the binary using strip. It's true that the DWARF info in particular has gotten larger in recent releases, because we've included more information to make debuggers work better. I don't think it has grown quite as rapidly as the table indicates - I think some of the rows already have some of the debug metadata removed in "Raw size".
Regardless, I would hope that anyone sensitive to networking costs at this level would be shipping around stripped binaries, so the growth in accurate DWARF info should not be relevant to this post at all.
That is, the right comparison is to the "Stripped" column in the big table. If you subtract out the strippable overheads and you take the "Dark + pclntab" as an accurate representation of Go-specific overhead (debatable but not today), then the situation has actually improved markedly since Go 1.12, which would have been current in April 2019 when the first post was written.
Whereas in Go 1.12 the measured "actual program" was only about 40% of the stripped binary, in Go 1.16 that fraction has risen to closer to 55%.
This is a marked-up copy of the table from the dr-knz.net revised post that at time of writing has not yet made it to cockroachlabs.com: https://swtch.com/tmp/cockroach-blog.png
I think the numbers in the table may be suspect in other ways, so I am NOT claiming that from Go 1.12 to Go 1.16 there has actually been a 15% reduction in "Go metadata overhead". I honestly don't know one way or the other without spending a lot more time looking into this.
But supposing we accept for sake of argument that the byte counts in the table are valid, they do not support the text or the title of the post. In fact, they tell the opposite story: the stripped CockroachDB binary in question has gotten smaller since April 2019, and less of the binary is occupied by what the post calls "non-useful" or "Go-internal" bytes.
> I would hope that anyone sensitive to networking costs at this level would be shipping around stripped binaries, so the growth in accurate DWARF info should not be relevant to this post at all.
Good point. I removed that part from the conclusion.
> If you subtract out the strippable overheads and you take the "Dark + pclntab" as an accurate representation of Go-specific overhead [...] then the situation has actually improved markedly since Go 1.12 [...] Whereas in Go 1.12 the measured "actual program" was only about 40% of the stripped binary, in Go 1.16 that fraction has risen to closer to 55%.
Ok, that is fair. I will attempt to produce a new version of these tables with this clarification.
> the stripped CockroachDB binary in question has gotten smaller since April 2019, and less of the binary is occupied by what the post calls "non-useful" or "Go-internal" bytes.
There's an explanation for that, which is that the crdb code was also reduced in that time frame.
Over on Lobsters, zeebo took the time (thanks!) to build the same version of CockroachDB with various historical Go toolchains, varying only the toolchain, and found that if anything the Go executables are getting smaller over time, in some cases significantly so.
v1.0 v20.2.0
1.8 58,099,688 n/a
1.9 57,897,616 314,191,032
1.10 57,722,520 313,669,616
1.11 48,961,712 233,170,304
1.12 52,440,168 236,192,600
1.13 50,844,048 214,373,144
1.14 50,527,320 212,699,656
1.15 47,910,360 201,391,416
The title of the article ("My Go executable files are still getting larger") appears to be literally untrue, at least read as a critique of Go itself. If they are getting larger, it's because new code is being added, not because the Go runtime or compiler is degrading in some way over time.
Yes this is a fair assessment, although I find it surprising (and enlightening) that you refer to “a critique of Go”. At no moment was the intent to critique Go specifically; the entire analysis is made of observation of the results of combining Go with specific (and varying) amounts of source code.
In any case, based on this discussion I have decided to amend the title and emphasize in the conclusion that the absolute size of the code+data for a fixed amount of source code has decreased between go 1.15 and 1.16.
edit: This is relevant to this discussion: https://sneak.berlin/20191201/american-communication/
- "These Go executable files are rather... bloated." - "70% of a couple hundred megabytes are copied around for no good reason"
I find it hard to believe that even a European software team would not consider those direct criticisms.
You do NOT write an article talking about "dark bytes" and a 70% "not useful" piece of binary for an Open Source project.
Specially one such as Golang where you can easily reach out to the creators at https://groups.google.com/g/golang-dev to ask for help understanding what your experiment tools can't explain...
Eg. """ Hey guys I am doing some digging with "such and such" tools and found that 70% of my binary size has no explanation. BTW this binary is Cockroach DB, an well known program in the Go ecosystem. How can I find out what are those bytes for? Is there any documentation about it, other than the source code itself? Or maybe some tooling that explains it? Or some other set of tools I should be using instead or on top of my current setup? """
I mean... there is no defense possible after writing such an article IMHO. Why didn't you ask first?
Having said that, when you deviate from the ubiquitous C standards for calling conventions and binary format layout, that comes with a price. I totally get that Go had to take such path, because Go binaries embed a non trivial runtime dealing, at the very least, with goroutines & GC support. But the price is there nonetheless: As you are not using a standard, you cannot rely on pre-existing tooling or documentation. You have to write your own.
It is understandable that writing such binary dissection documentation or tooling (or both) might not be a top priority compared to other more pressing matters for the Go Language. But this kind of thing becomes technical debt and as such, the longer you take to pay it, the more expensive it becomes. For instance: - This happened, and might have damaged the Go Language reputation, at least temporarily for some people. - I am surprised how could the Go team (or community) achieve improvements at all in the binary size work without tools to properly dissect binaries or detailed documentation. I am guessing it relied on the original programmers of those bits to have a very clear idea of the binary layout uploaded in their brains, so they did not need to re-grok all the sources again... with time that becomes more and more difficult, people forget stuff, move to other projects, etc.
I think it would be wise to prioritize this somehow. If the Go team cannot take it for now, maybe they can promote it as a good Go community project to be done ASAP, and promise to help the takers with all info and reviews needed.
Or maybe the article writers should take up the challenge, to fully redeem themselves ;-p
yes this is acknowledged in the OP
> We (the Go team) did not “recompress” pclntab in Go 1.15.
There's now less redundancy in the funcdata, so in my book less redundancy = more compression.
> We did not remove pclntab in Go 1.16.
Correct; it is not "removed"; instead the advertised size of the symbol has been reduced to zero. Maybe the data is still there, but it's not accounted any more.
Changed in the text. (The correction is already present in the original version of the analysis, and the cockroach labs copy should be updated soon)
> we never claimed “pclntab has been reduced to zero”, which is presented in the article as if a direct quote.
Correct, there was indeed no such claim. Removed the quotes and rephrased that paragraph.
> If the 73% of the binary diagnosed as “not useful” were really not useful, a reasonable demonstration would be to delete it from the binary and see the binary still run. It clearly would not.
1) the phrase "non-useful" was a mistake. There is no definite proof it is non-useful, as you pointed out. Corrected in the text.
2) see discussion below - the demonstration is more complicated than that, as removing 100 bytes where just 1 byte is necessary will break the executable in the same way as removing 100 necessary bytes.
I think the proper next step here is to acknowledge that the problem is not "usefulness" but rather accountability.
> The big table seems to claim that a 40 MB Go 1.8 binary has grown to a 289 MB Go 1.16 binary. That’s certainly not the case. More is changing from line to line in that table than the Go version.
Correct. Added a note to emphasize this fact.
> Overall, the claim of “dark bytes” or “non-useful bytes” strikes me as similar to the claims of “junk DNA”. They’re not dark or non-useful.
Let's forget about "non-useful", this was a mistake and will be corrected. The word 'dark' is still relevant however. The adequate comparison is not "junk DNA", but instead "dark silicon":
https://ieeexplore.ieee.org/abstract/document/6307773
We're talking about a general % of executable size that's necessary for a smaller % of use cases in program function.
I'm all for trade-offs, but IMHO they should be transparent.
The title of the post is "Go Executable Files Are Still Getting Larger". Upon further reading and conversation here it seems this is possibly not true, nor what the post is about. If we believe Russ's comments, Go executable sizes haven't increased much in general. Perhaps the reason you're seeing increases in Cockroach DB is because you keep writing more code for Cockroach DB?
Now the point has shifted to this notion of "dark bytes". So the article is about ... how the way you previously diagnosed the contents of binaries doesn't work anymore? That's fine and legitimate, but it seems like the point is over-extrapolated to become a criticism of the Go team.
Russ's example was just the "gofmt" program.
> Perhaps the reason you're seeing increases in Cockroach DB is because you keep writing more code for Cockroach DB?
If that was the only reason, then the % overhead would remain constant-ish. But it is increasing. So there is a non-linear factor for _some_ go programs (like cockroachdb) and it's still unclear what that factor is.
In the same way, the functab data in Go is not used all the time either, only when generating stack traces.
Also since that original article from 2011 was published, the phrase "dark silicon" was extended to designate silicon IP which is not directly necessary for a given target application but is embedded for the occasional use by a niche in the same market.
In the same way, all languages (not just Go) embed constructs in generated code that are there only to handle edge cases in certain applications/deployments, and are inactive for 90%+ of executions.
Might it be possible to stream binaries or to detect junks which could be unloaded like an json parser which is only needed when reading json
Because even without a swap partition/file, the whole executable will not block physical memory, but will page in/out as needed. And whole sections of it will never be loaded at all.
The DWARF data is currently so represented, and so was pclntab prior to 1.16.
Today, the DWARF data is still present; the symbol for pclntab has an advertized size of zero, and the amount of data not represented in the symbol table and ELF section headers has grown.
> If the 73% of the binary diagnosed as “not useful” were really not useful, a reasonable demonstration would be to delete it from the binary and see the binary still run. It clearly would not.
Probably not if all of it was removed at once.
It could be that just 5% of it is useful and removing all of it would produce a non-working binary. What does the experiment prove exactly?
Look you can claim that "having the necessary metadata for garbage collection and reflection in a statically-compiled language takes up a significant amount of space" but without clear evidence of how much space that is, with proper accounting of byte usage, this claim is non-falsifiable and thus of doubtful value.
The article made the claim that 70% of space is wasted "dark bytes". The article should prove the claim, which it did not. It's an extraordinary claim that really requires more evidence than just an off-hand napkin calculation and talk about mysterious "dark bytes".
It takes very little time to write up something that's wrong.
It takes much more time to write a detailed rebuttal.
What you're doing here is pretty much the same trick quacks, young-earth creationists, and purveyors of all sorts of pseudo-scientific claims pull whenever they're challenged. Any fool can claim the earth is 6,000 years old. Proving that it's actually several billions years old requires deep insight in multiple branches of science. People stopped doing this after a while as it's so much effort and pointless as they're not listening anyway, so now they pull the "aha, you didn't falsify my claim about this or that bullshit I pulled out of my ass therefore I am right" zinger and think they look Very Smart And Scientific™.
But that's not how it works.
Also just outright disbelieving people like this is rather rude. You're coming off really badly here and your comment has the strong implication that Russ is outright lying. Yikes!
This is incorrect. The claim is that the bytes are either non-accounted, or motivated by technical choices specific to Go.
> What you're doing here is pretty much the same trick quacks [...]
Look the article has some measurements with numbers which you can readily reproduce on your own computer, and the methodology is even described. The main claim is that "it's unclear what these bytes are about". The previous claim that they were "non-useful" was retracted. The data is there, and there's a question: "What is this data about?"
The text is even doubling down by spelling out "there's no satisfying explanation yet".
> outright disbelieving people like this is rather rude
We're not in the business of "believing" or "disbelieving" here I think? There's data, there's measurements, and there are explanations.
After my comments and that of others, Russ provided a more elaborate, more detailed (and at last, falsifiable in the positive, epistemological sense of the word) explanation deeper in the thread. Now we can make the work of looking into it and check the explanation.
> your comment has the strong implication that Russ is outright lying
Your understanding is flawed then? There was no assumption of lies implied.
I respectfully disagree. I believe there is value in pointing out the false claims in a long blog post even when there isn't time to write a full-length rebuttal.
Oh, you don't want to do that? That's not a surprise. Neither do I. Definitely not on my agenda today.
But I'm not making wild accusations. If you're going to, you probably shouldn't be surprised when we're not exactly impressed.
The compiler is all open, and as such things go, fairly easy to read. "As such things go" is definitely doing some heavy lifting there, but, still, for a compiler of a major language, it's a relatively easy read.
The vague intimation that there's something hidden and sneaky going on is hard to give much credence to.
It's an ELF binary; all that's relevant are the program/segment headers and dynamic table. The section headers and non-dynamic symbol table are just there for orthogonality and to make the debugger's life a little easier (and the debugger would much prefer DWARF data and doesn't care about the section headers, tbh)
As explained in OP, the sum of sizes advertised in the symtable and ELF section headers does not add up to the final binary size. The shotizam tool is thus blind to that difference.
> At this time, I do not have a satisfying explanation for this “dark” file usage.
The author's journey of starting with "nm --size", discovering "dark" bytes, and wanting to attribute them properly, is exactly what led me to create and invest so much effort into Bloaty McBloatface: https://github.com/google/bloaty
Bloaty's core principle is that every byte of the file should be attributed to something, so that the sum of the parts always adds up to the total file size. If we can't get detailed symbol, etc. information for a given region of the file, we can at least fall back to describing what section the bytes were in.
Attributing all of the bytes requires parsing much more than just the symbol table. Bloaty parses many different sections of the binary, including unwind information, relocation information, debug info, and the data section itself in an attempt to attribute every part of the binary to the function/data that emitted it. It will even disassemble the binary looking for references to anonymous data (some data won't make it into the symbol table, especially things like string literals).
I wrote up some details of how Bloaty works here: https://github.com/google/bloaty/blob/master/doc/how-bloaty-.... The section on the "Symbols" data source is particularly relevant here:
> I excerpted two symbols from the report. Between these two symbols, Bloaty has found seven distinct kinds of data that contributed to these two symbols. If you wrote a tool that naively just parsed the symbol table, you would only find the first of these seven:"
The author's contention that these "dark" bytes are "non-useful" is not quite fair. There are plenty of things a binary contains that are useful even though they are not literally executable code. For example, making a binary position-independent (which is good for security) requires emitting relocations into the binary so that globals with pointer values can be relocated at program load time, once the base address of the binary is chosen. I don't know if Go does this or not, but it's just one example.
On the other hand, I do agree that the ability to produce slim binaries is an important and often undervalued property of modern compiler toolchains. All else being equal, I much prefer a toolchain that can make the smallest binaries.
Bloaty should work reasonably well for Go binaries, though I have gotten some bug reports about things Bloaty is not yet handling properly for Go: https://github.com/google/bloaty/issues/204 Bloaty is just a side thing for me, so I often don't get as much time as I'd like to fix bugs like this.
I mean... Im genuinely curious if this is a "we have extra engineering resources and can explore/complain about this" or "we have a client who is running cockroachdb and can't handle a 172mb binary install for a database server".
Is there really someone out there who installs Cockroach (a global distributed auto-sharded database) and thinks twice about 172mb of disk space?
Sure, it'd be nice to have smaller binaries but outside of some embedded applications Go's binaries sizes are well within the nothing-burger range for most compute systems.
Remember: cockroachdb is always synchronizing data across the cluster, that 175mb of ingress to start up a DB node, probably pales in comparison to data synchronization/relocations that happen on a cluster. Which is why worrying about ingress/egress costs over binary size is nonsense here too.
The bandwidth you need to run a distributed database cluster could download 172mb binary in milliseconds. If your node initiation time for DB failovers needs anything faster, you're doing something wrong.
There are stakeholders to this problem, Cockroach probably isn't one.
In the end this all ends up because it is for all go binaries. I’ve come appreciate attention for leanness because in the end it does add up.
So you’re definitely correct that core Go is not an option, but options exist within the “greater metropolitan area” that’s built up around downtown.
These are among the benefits of having a relatively simple language and a 1.0 compatibility commitment, I think.
[1]: https://tinygo.org/ their FAQ is quite good.
A current side project of mine uses golang's wasm. Not a big codebase, but the wasm is 2.7MB brotli'ed. Certainly huge to me (I'm sure it's almost in the lean and mean camp compared to the average website today, though).
Which they are loathe to do
I think it is exactly this mindset that caused the current situation (that the 2/3 of the compiled binaries are useless to the users).
This is only on HN's homepage because of the langauge flame wars. It's a garbage post.
That the bytes are not visible in the symbol table is inarguable, that they are useless is a highly contentious statement and very probably wrong.
Does the author think the Go authors are stupid blubbering idiots who someone missed this huge elephant-sized low-hanging fruit? Binary sizes have been a point of attention for years, and somehow missing 70% wasted space would be staggeringly incompetent.
Reminds me of the time in high school when one of the my classmates ended up with a 17A doorbell in some calculations. I think he used the wrong formula or swapped some numbers. The teacher, quite rightfully, berated him for not actually looking at the result of his calculation and judging if it's roughly in the right ballpark, as 17A is a ludicrous amount of power for a doorbell. Anyone can see that's just widely wrong.
If this story had ended up with 0.7%, sure, I can believe that. 7%? Unlikely and I'd be skeptical, but still possible I suppose. *70%* Yeah nah, that's just as silly as a 17A doorbell.
This huge 70% number should have been a clue to the author themselves too that they've missed something.
Meanwhile half of the world is pushing images by nvidia, intel and amd around for their machine learning software:
Intel OneAPI runtime libraries: 4.74GB (or 18.4GB for compilers) CUDA runtime libraries: 1.92GB (or 4.2GB for compilers)
These go binaries are still relatively small
Last but by no means least there are in total 13MB of autogenerated functions of the colexec package, each of which is over 100KB long, which are autogenerated and share virtually all of their code. These are an obscene waste of code space and undoubtedly de-deuplicating this code would not just reduce code size but also speed up the program, due to icache trashing.
Then, whenever a debugger connects to a binary, it can simply download the symbols as required.
And for the 99.9% who don't need debug info, it isn't needlessly shipped.
Microsoft invented this in the 90's...
I guess it is just a tradition with Go, rediscovering history.
Does anyone have a source for this? As it still appears to be there
- Go 1.15 https://i.imgur.com/3YlZGOk.png
- Go 1.16 https://i.imgur.com/gGYsj32.png
(This is derived from Russ' discussion above.)
CPython doesn't generate anything, and the binary installers (including docs and all) are about 30MB. Hell, the 64b embeddable package for windows (https://docs.python.org/3/using/windows.html#the-embeddable-...) is 16MB uncompressed.
It would be nice to be able to decide on those trade-offs ourselves. I mostly write web servers in Go, which (as the article says) are executed rarely, so init time really doesn't matter to me. But I've been looking at writing some desktop apps in Go, and then init time will matter.
I know for a good long time Go wasn't even stripping out unused functions, e.g., if you used any of the "strings" standard module you got the whole thing compiled in. I don't know if that's still the case, but it would be another source of size problems.
I'm also not sure why you're talking about init time; binary size doesn't necessarily factor in to that very much. The things that make the Go binaries large also tend to lean in favor of faster initialization anyhow. A lot of these binaries won't even necessarily be read in to memory, or have to stay there in the event of swap pressure, since they're already disk-backed memory pages that can be never loaded in the first place, or cheaply evicted by the virtual memory system if space is needed.
However, once you exceed the 10-20Mb regime, I seem to find more 20-200Mb Go bins in the wild. This can be misleading, since the Go world is a fan of packing assets into binaries, eg for web GUIs.
What dings Go bins on init time is the Go runtime. Still, it's rarely noticeable unless you are firing thousands of times a second.
Presumably a few mb of disk usage also doesn't matter then? I also write web services, but I do care about the init time precisely because I want to be deployments to take as little time as possible so that we can deploy (and rollback) many times per day with relatively simple automation. That said, the bottleneck to fast deployments isn't the binary starting up, but the machine pulling the executable artifact, so the binary sizes do matter to me. That said, very often these executable artifacts are a Docker image, which tend to come with a lot more bloat than one will find in a Go binary, so step 1 is getting your Go binary on a scratch image.
I don't use Docker to deploy, because it's just a single executable file (and a bunch of templates, though I'm looking at embedding those). One of the reasons I'm reluctant to go down the Docker road is because it's going to add more time to my deployment.
It's perfectly fine to compile a Go binary and stick it into a Docker container on its own; it is not obligatory for a Docker container to contain a full Linux installation. I've got a couple of Docker files that are pretty much just
FROM scratch
ADD my_binary /
It is also a convenient way of knowing exactly what your dependencies are... for instance I have several Go containers that also have to include a trusted cert store so they can access remote HTTPS resources correctly. Since you don't need a full Linux install to run a Go binary, it's very easy to use Docker as a complete, human-comprehensible manifest of exactly what is in that container.
Yeah, I don't advocate Docker for its own sake, but my organization deploys everything via Kubernetes because it's simpler than having a bespoke orchestration strategy/toolchain for each project, but if you're a one-project shop then containerization probably doesn't add a lot of value (although I still haven't figured out a streamlined, reliable way to provision/configure VMs).
Can be a good start https://blog.filippo.io/shrink-your-go-binaries-with-this-on...
Do you use rsync [1]? I ask because most of my collegues don't and they take minutes to deploy what I usually do in seconds.
Go is cheating a bit on this one by heavily caching everything. Building in fresh container is quite slow (ok, maybe not c++ slow but still much slower then C).
Always having to build anything due to static linking does not help either.
I don't think there's an easy either-or answer to questions like this, but broadly language design seems to be about finding a sweet spot while balancing lots of trade offs, so to get fast compiles you're going to make trade-offs in other areas of the language and implementation. I imagine if the compilation time budget was higher there'd be some more space for binary pruning passes.
It mirrors their GC philosophy.
But if there some flags to tell the compiler to compile slowly and produce a smaller executable, that would be awesome for final builds that need to be shipped across the internet.
Just zero them out and they'll compress to nothing. Even better, with a sparse file aware tool like tar, they won't even use disk space.
It is a very annoying thing for a C++ programmer, which can dynamically link operating system libraries at will.
- Go's design, based on both C compilers and Inferno's limbo
- /proc
- utf-8
- 9p
Rio's foundations come from the Blit.
Unix 8/10 was not a big success, but a lot of ideas from that went into Plan9.
Poor design decisions result in a language that gets extremely bloated over time, forcing you to use features that you don’t want to.
The better approach is to make these features optional, such as through a standard library.
> Sadly, the removal of pclntab in Go 1.16 actually transferred the payload to the “dark” bytes.
I surely would have expect better from programming language designers/developers than this. Sounds like they just moved the problem from one place to another.
{kind=link}
{kind=link}
{kind=link}