https://security.stackexchange.com/questions/198005/is-plaid...
https://airflow.apache.org/docs/apache-airflow/stable/concep...
Airflow also focuses a bit more on being a multi-process data pipeline with workers rather than a way to drive user experiences with rendering, localization, user interaction, etc.
1. How you implemented this on the backend? Did you consider using something like Temporal, AWS Simple Workflow, or AWS Step Functions?
2. Interested in how you're avoiding (waiting) on network calls on each action. You mentioned it was coming in next post.
3. How are you managing multiple workflows? Does a common child graph make sense for a common workflow?
Given this already a major change in our client<>server interaction model and that we didn't want to _fully_ rewrite the entire world, we didn't consider additional major changes to our existing backend services strategy (Go services + RPC) as part of this project. We had a bunch of backend logic and common code we wanted to reuse across Flex Link and the legacy endpoints, which gives us a stepwise mechanism for future refactors once the old APIs are turned down.
Once this rolls out to 100%, the new API boundaries do allow us to refactor the backend into something more like you suggest — leveraging step functions, lambdas etc if desired.
> 2. Interested in how you're avoiding (waiting) on network calls on each action. You mentioned it was coming in next post.
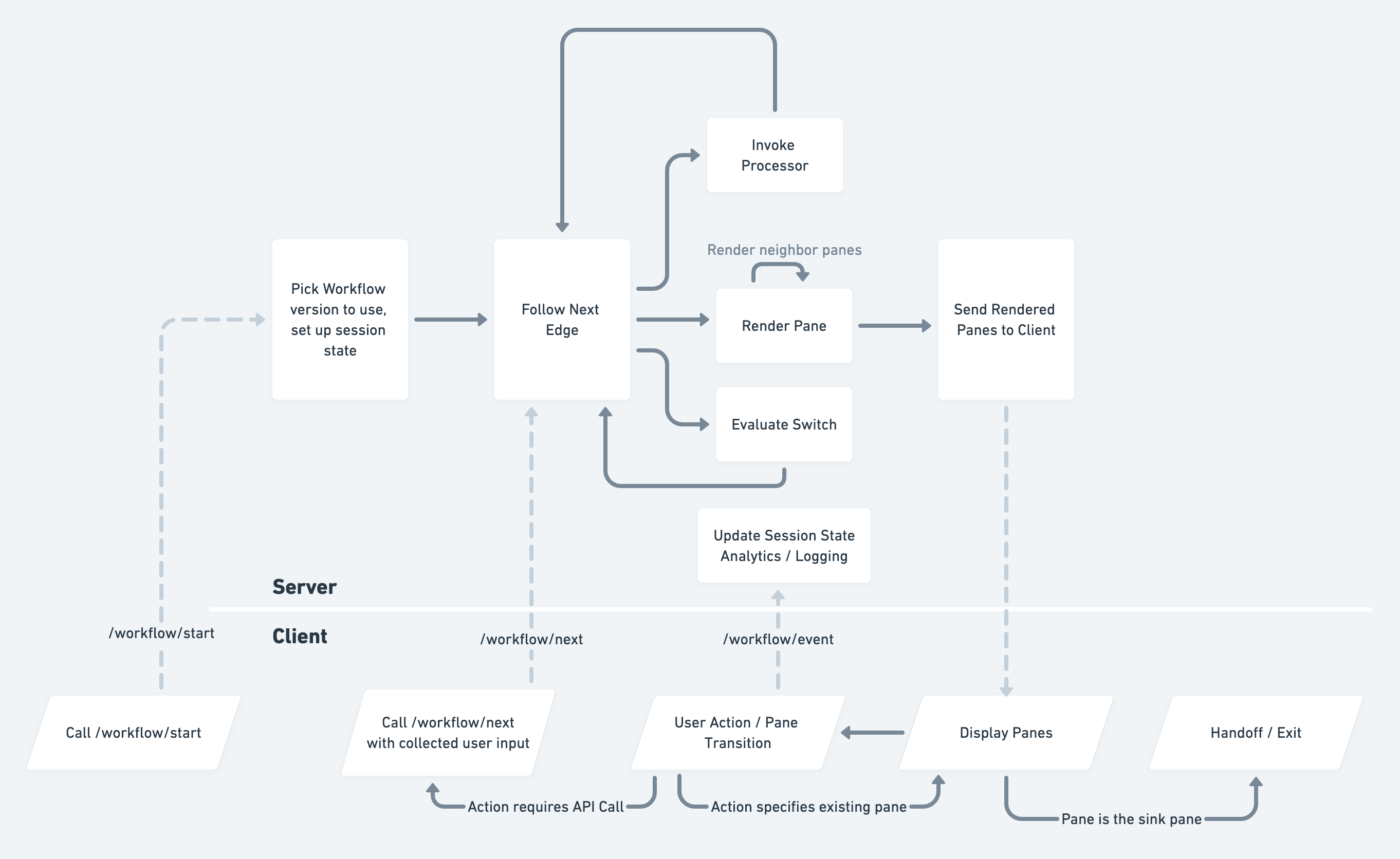
Yes! Full details of that would take a dedicated post. However, if you look at the "Client Rendering Loop" diagram in the post ( https://images.ctfassets.net/zucqsg1ttqqy/5kp6LibAllW1YW69jT... ) you'll see there is a "render neighbor panes" loop in the flow. At the point where we've walked the graph and encountered a pane, we can do a quick breadth-first-search to render out neighboring panes (that don't have a processor in between) and serve those all to the SDK. We all them "additional panes". The response includes a map from "action" to "additional pane" so the SDK can know whether to hit the API or use an already-provided additional pane. (this is in the diagram as well)
The nice part is, clients don't _have_ to implement this functionality. They can always hit the server each time they want the next pane. But as a performance optimization they can leverage the additional panes to render many things locally.
> 3. How are you managing multiple workflows? Does a common child graph make sense for a common workflow?
We use the expanded semantic versioning in the post for teams to have their own versioned workflow namespace. On the `workflow/start` call, we have a dispatcher that can pick which workflow to serve based on the provided configuration, SDK version, platform, experiments, etc.
We don't yet support subgraphs for common chunks of a workflow but it is definitely in our roadmap and would allow teams to share common pieces of the graph.
Yes — it is essentially a UI component (and the only node that represents UI).
> And I am assuming there are tests to catch cases where a new pane is defined in the backend, but not in the SDK (or I suppose, how do you deal with any discrepancy)?
Great question! Because we use proto, the SDK and the backend share the same pane definitions. So we can't have a case where they don't match in the repo. However, SDKs that have already shipped obviously can't be updated with new panes. To handle this, we have a piece of the backend service called the "dispatcher" whose job it is to look at the initial /start request and determine which workflow should be used for that specific client.
Let's say a very old Android SDK is issuing a /start request. The dispatcher knows the version of the SDK requesting a workflow and programmatically can determine which major version of workflow graphs it supports, and pick an appropriate (older) workflow to send back where we know all panes are supported by the SDK.
We also have an escape hatch where the backend can tell an older SDK "actually, you're so old you should fallback on a webview implementation to get the latest and greatest experience".
A state machine will typically fully describe all the state at any given node in it. i.e. there's no additional state or context not represented by the state machine itself.
In our case, we have (1) the directed graph and (2) the session state. These two are related but don't have a direct correlation. The session state accrues new values as the graph is walked. As an example, theoretically the user could walk through a graph that has a cycle and get back to an earlier node but the session state would be different. In that case the same node would be "current" but there would be a different session state the second time it was visited.
However, to my limited knowledge of this, BPMN doesn't quite differentiate between its activities in terms of "does this need user interaction" vs "process this thing". In our case, we have pane nodes for the "need user interaction" activity and processor nodes for the "process this thing" activity.
User interaction is a distinct BPMN Activity Type, so BPMN can make this distinction quite unambiguously. Concrete BPMN implementations, IIRC, use varying amounts of the spec and have varying degrees to which Activity types are functionally rather than merely visual distinguished, so a particular BPMN tool may or may not make the distinction or treat it as significant.
So how come going to production with you is a three month process involving endless spreadsheets and email exchanges? not at all as presented on website.
You've left your onboarding / compliance team behind while focusing on the cool stuff.
(VPEng at Plaid)
Security - policies, architecture, breach procedures, external review, GDPR compliance, hosting structure, cryptography.
Compliance - proove registration with different compliance bodies, proof of insurance (professional indemnity AND cyber), AML measures, KYC measures, proof of purchase of monitoring systems..
Identity - provide information on ALL directors and shareholdeing structure, provide proof of address and identity of 2 of them, name a company signatory and provide proof of identity and address for him as well.
And more and more... took us 2 months just to compile all the information in endless back-and-forth email conversations.
{kind=link}