(I realize that choosing the most likely word wouldn't necessarily solve the issue, but choosing the most likely phrase possibly might.)
Edit, post seeing the video and comments: it's beam search, along with temperature to control these things.
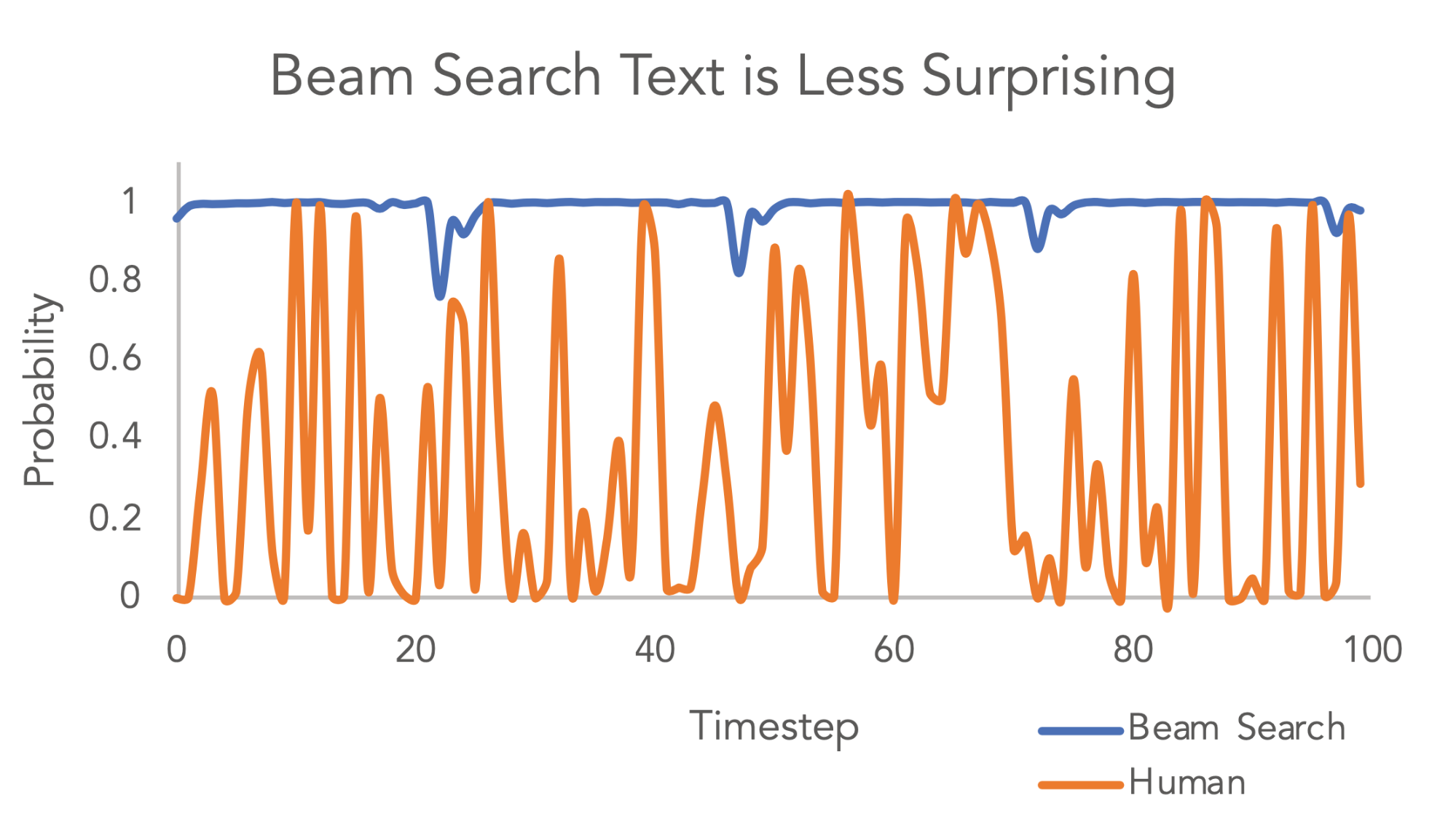
Temperature and top_k (two very similar parameters) were both introduced to account for the fact that human text is unpredictable stochastically for each sentence someone might say as such - as shown in this 2021 similar graph/reproduction of an older graph from the 2018/2019 HF documentation: https://lilianweng.github.io/posts/2021-01-02-controllable-t...
It could be that beam search with much longer length does turn out to be better or some merging of the techniques works well, but I don't think so. The query-key-value part of transformers is focused on a single total in many ways - in relation to the overall context. The architecture is not meant for longer forms as such - there is no default "two token" system. And with 50k-100k tokens in most GPT models, you would be looking at 50k*50k = A great deal more parameters and then issues with sparsity of data.
Just everything about GPT models (e.g. learned positional encodings/embeddings depending on the model iteration) is so focused on bringing the richness of a single token or single token index that the architecture is not designed for beam search like this one could say. Without considering the training complications.
At the output of an LLM the raw next-token prediction values (logits) are passed through a softmax to convert them into probabilities, then these probabilities drive token selection according to the chosen selection scheme such as greedy selection (always choose highest probability token), or a sampling scheme such as top-k or top-p. Under top-k sampling a random token selection is made from one of the top k most probable tokens.
The softmax temperature setting preserves the relative order of output probabilities, but at higher temperatures gives a boost to outputs that would otherwise have been low probability such that the output probabilities are more balanced. The effect of this on token selection depends on the selection scheme being used.
If greedy selection was chosen, then temperature has no effect since it preserves the relative order of probabilities, and the highest probability token will always be chosen.
If a sampling selection scheme (top-k or top-p) was chosen, then increased temperature will have boosted the likelihood of sampling choosing an otherwise lower probability token. Note however, that even with the lowest temperature setting, sampling is always probabilistic, so there is no guarantee (or desire!) for the highest probability token to be selected.
Can you explain how it chooses one of the lower-probability tokens? Is it just random?
That said, LLM reach their current performance despite this limitation.
An example is Beam Search:https://www.width.ai/post/what-is-beam-search
Essentially we keep a window of probabilities of predicted tokens to improve the final quality of output.
I have no idea why you say this. Most of our pipelines will run greedy, for reproducibility.
Maybe we turn the temp up if we are returning conversational text back to a user.
Thats basically chunking or at least how it starts. I was impressed by the ability to add and subtract the individual word vector embeddings and get meaningful results. Chunking a larger block blends this whole process so you can do the same thing but in conseptual space the so take a baseline method like sentence embedding and that becomes your working block for comparison.
If you haven't seen the first few chapters, I cannot recommend enough.
I was ignorant enough to try and jump straight in to his videos and despite him recommending I watch his preceeding videos I incorrectly assumed I could figure it out as I went. There is verbiage in there that you simply must know to get the most out of it. After giving up, going away and filling in the gaps though some other learnings, I went back and his videos become (understandably) massively more valueable for me.
I would strongly recommend anyone else wanting to learn neural networks that they learn from my mistake.
Prior discussion: https://news.ycombinator.com/item?id=38505211
Thank you for sharing.
{kind=link}