Bytedances crawler (Bytespider) is another one which disregards robots.txt but still identifies itself, and you probably should block it because it's very aggressive.
It's going to get annoying fast when they inevitably go full blackhat and start masquerading as normal browser traffic.
doesn't seem supported by the citation, https://www.404media.co/websites-are-blocking-the-wrong-ai-s...
Some more discussion https://news.ycombinator.com/item?id=41060559
(disclaimer: I wrote this blog post)
They even respect extended robots.txt features like,
User-agent: *
Disallow: /library/*.pdf$
I guess ideas like creative commons and sharing go away when the smell of money enters the water. Better lock all your text behind paywalls so the evil corporations won't get it. Just be aware, for every incorporated entity you block you're blocking just as many humans with false positives, if not more. This anti-"scraping" hysteria is mostly profit motivated.
That seems overly reductive.
First, it sounds like you're insinuating that the people claiming the bots are causing actual disruption to their operations are lying. If that's your intent, some amount of evidence for that would be welcome.
Second, lots of people don't want their content to be used to train these models for reasons that have nothing whatsoever to do with money. Trying to avoid contributing to the training of these models is not the equivalent of rejecting the idea of the free exchange of information.
I qualified my statement but you've chosen to ignore that. I've been paying attention to the Anthropic bots closely for a (relatively) long time and this mastodon group's problems come as a surprise to me based off that lived experience. I don't doubt the truth of their claims. I looked at https://cdn.fosstodon.org/media_attachments/files/112/877/47... and I see the bandwidth used. But like I said,
>I'm not saying my dozens of run-ins with the anthropic bots (there have been 3 variations I've seen so far) are totally representative,
My take here is that their one limited experience also isn't representative and others are projecting it on to the entire project due to a shifting cultural perception that "scraping" is something weird and bad to be stopped. But it's not. If it were me I'd be checking my webserver config to be sure robots.txt is actually being violated. And I'd check my set per user-agent bandwidth limits in nginx to make sure they matched. That'd solve it. I'm sure the mastodon software has better solutions even if they haven't solved their own DDoS generating problem since 2017 (ref: https://github.com/mastodon/mastodon/issues/4486)
funny thing - with wasm, the web won't be scrappable.
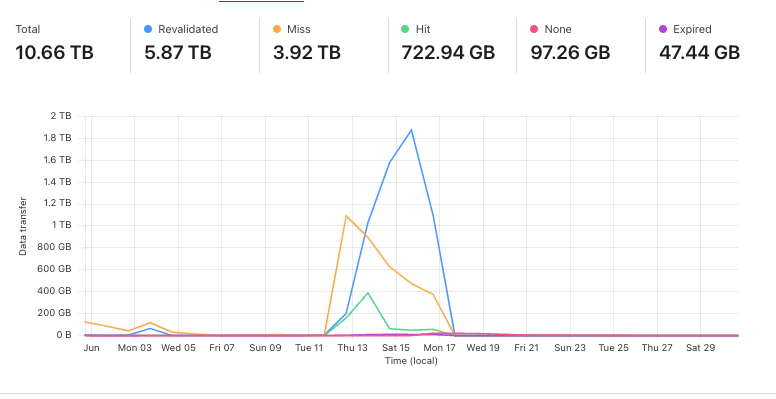
https://fosstodon.org/@readthedocs/112877477202118215
A bunch of the traffic hit the origin.
{kind=link}