In other words, this solves the problem of "one hit wonders" getting out of the cache quickly, but that basically already happened with the reddit workload.
The exception to that was Google, which would scrape old pages, and which is why we shunted them to their own infrastructure and didn't cache their requests. Maybe with this algo, we wouldn't have had to do that.
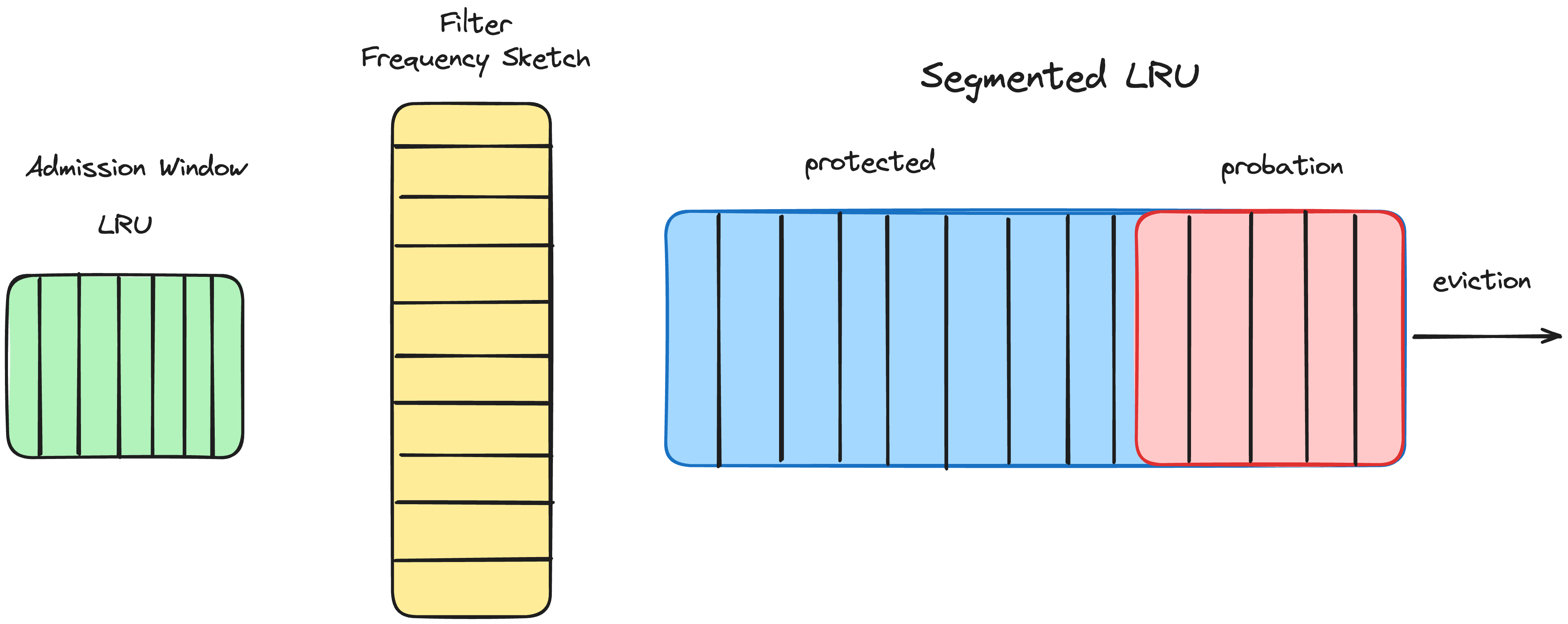
Although if that’s your concern you can probably just add a smaller admission cache in front of the main cache, possibly with a promotion memory.
guessing post bodies and link previews feels too easy.
comment threads? post listings?
was there a lot of nesting?
it sounds like you're describing a whole post--use message, comments, and all--for presentation to a browser or crawler.
(sorry, saw the handle and have so many questions :D)
Shoutout to author Ben Manes if he sees this -- thanks for the great work!
It had a clever caching algorithm that favored latency over bandwidth. It weighted hit count versus size, so that given limited space, it would rather keep two small records that had more hits than a large record, so that it could serve more records from cache overall.
For some workloads the payload size is relatively proportional to the cost of the request - for the system of record. But latency and request setup costs do tend to shift that a bit.
But the bigger problem with LRU is that some workloads eventually resemble table scans, and the moment the data set no longer fits into cache, performance falls off a very tall cliff. And not just for that query but now for all subsequent ones as it causes cache misses for everyone else by evicting large quantities of recently used records. So you need to count frequency not just recency.
And totally legibility and/or simplicity. I'll take something I can reason about and maintain over something more complicated just to eek out a tiny better hit ratio. That said, if you're caching at scale your 0.05% hit ratio can be a big deal.
As a matter of personal taste/opinion I also shy away from close loop systems. Feedback makes things complicated in non-intuitive ways. Caffeine seems neat in terms of using feedback to adjust the cache to the workload - as always test with your workloads and pick what is best for your situation.
The thing is that the math changes when the system is saturated. The closer you get to tipping over, the more each new request costs. I feel like I can clearly recall times when I had to make a Sophie's Choice between p50 and p95 times because of issues of this sort.
Love love love this - I really enjoy reading articles where people analyze existing high performance systems instead of just going for the new and shiny thing
> Caching is all about maximizing the hit ratio
A thing I worry about a lot is discontinuities in cache behaviour (simple example: let’s say a client polls a list of entries, and downloads each entry from the list one at a time to see if it is different. Obviously this feels like a bit of a silly way for a client to behave. If you have a small lru cache (eg maybe it is partitioned such that partitions are small and all the requests from this client go to the same partition) then there is some threshold size where the client transitions from ~all requests hitting the cache to ~none hitting the cache.)
This is a bit different from some behaviours always being bad for cache (eg a search crawler fetches lots of entries once).
Am I wrong to worry about these kinds of ‘phase transitions’? Should the focus just be on optimising hit rate in the average case?
Thankfully most workloads are a relatively consistent pattern, so it is an atypical worry. The algorithm designers usually have a target scenario, like cdn or database, so they generally skip reporting the low performing workloads. That may work for a research paper, but when providing a library we cannot know what our users workloads are nor should we expect engineers to invest in selecting the optimal algorithm. Caffeine's adaptivity removes this burden and broaden its applicability, and other language ecosystems have been slowly adopting similar ideas in their caching libraries.
[1] https://github.com/ben-manes/caffeine/wiki/Efficiency#adapti...
That project was the beginning of the end of my affection for caches. Without very careful discipline that few teams have, once they are added all organic attempts at optimization are greatly complicated. It’s global shared state with all the problems that brings. And if you use it instead of the call stack to pass arguments around (eg passing ID instead of User and making everyone look it up ten times), then your goose really is cooked.
When you look up the same value 10 times, you not only pollute the flame graphs and call counts which makes proving that a better algorithm is necessary or has any effect much harder, but more importantly, you could get 3 different states and try to make a bunch of updates based on what should be mutually exclusive states in the system. That's the global shared state problem.
When you look up a value once and remember it throughout a calculation, it may not be the current state, but at least you have a clean snapshot of the data. Which in situations such as cancelling an account immediately after getting one last discount on a purchase, well, we know which scenario the customer probably meant.
There is no point fixing a "this could be slow if we have more than 65535 users" if you currently have 100 users.
I usually add a few pointers to the document on how to increase the scaling limit a bit without major rebuilding (e.g. make this cache size 2x larger). Those are useful as a short term solution during the time needed to build the real next version.
I think the only way to approach this problem is statistically, but average is a bad metric. I think you’d care about some high percentile instead.
[1] https://github.com/ben-manes/caffeine/blob/master/simulator/...
[2] https://github.com/ben-manes/caffeine/actions/runs/130865965...
https://web.archive.org/web/20250202094451/https://adriacabe... (images are cached better here)
Passive-Aggressive Stalebot marches into the middle of an _active_ thread and announces that the issue is now stale/dead and everyone should go away.
I get that on large projects there’s a non-trivial percentage of issues which amount to “I’m holding it wrong, didn’t actually read the log messages, or the manual, fix it for me pls” which are just unhelpful noise. However more often than not they take every other thread- including important ones, with them.
https://github.com/kovidgoyal/kitty/issues — 0.239% vs 0.137%
https://github.com/kovidgoyal/kitty/issues — 0.729% vs 0.317%
For something a bit lower level, try:
It's what powers the sketch-like look from many of the sites above.
{kind=link}