That is a huge claim to make with no evidence.
I researched what you said, and I have found no statement to that effect in their paper[0], on huggingface[1], twitter[2], WeChat[3], or in their news release[4].
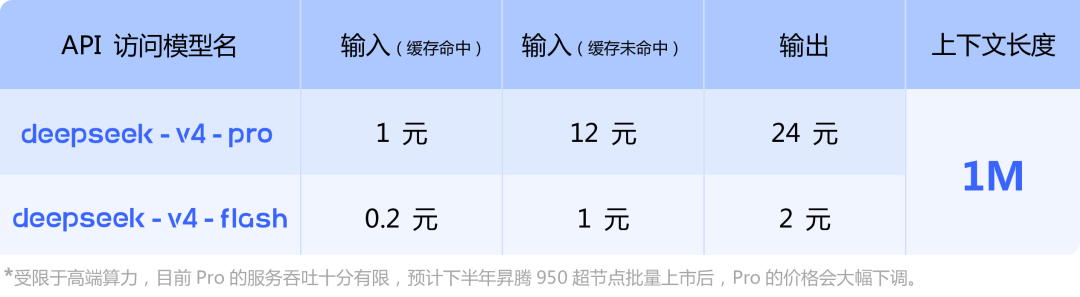
They only mention as a footnote in only the Chinese version of their news release that they plan to reduce inference costs with the Ascend 950 supernode when it releases[5]. The only mention of Huawei in their paper is that they validated a technique to lower interconnect bandwidth on Ascend NPUs and Nvidia GPUs[6].
[0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...
[1] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
[2] https://xcancel.com/deepseek_ai/status/2047516922263285776
[3] https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg
[4] https://api-docs.deepseek.com/news/news260424
[5] https://api-docs.deepseek.com/zh-cn/img/v4-price.png
[6] Page 16
{kind=link}