Gemini 2.5 flash: $0.30/$2.50
Gemini 3.0 flash preview: $0.50/$3.00
Gemini 3.5 flash: $1.50/$9.00
Interesting pricing direction. I don't think we have ever seen a 3x price increase for in the immediate next same-sized model (and lol @ 3 only ever getting a preview).
3.5 flash costs similar to Gemini 2.5 pro which was $1.25/$10
Gemini 2.5 flash (27 score): $172 (1.0x)
Gemini 2.5 pro (35 score): $649 (3.8x)
Gemini 3.0 Flash (46 score): $278 (1.6x)
Gemini 3.5 Flash (55 score): $1,552 (9.0x or 2.4x compared to 2.5 pro)
This is a massive price increase... 5.6x compared to Gemini 3.0 Flash
People really can’t wait to be the next Zynga
Or maybe they think because their benchmarks are good they can ramp up the prices. Seems like they don’t have the market share to justify a move like that yet to me.
My guess: it's the price at which they make more money than if they rent the TPUs to other companies.
The Gemini team has had trouble securing enough TPUs for their user's needs. They struggle with load and their rate limits are really bad. Maybe at a higher price, they have a better chance at getting more TPUs assigned?
Just because you are vertically integrated doesn't mean you get to discount the one business units products to the other. Doing so discounts the opportunity cost you pay and is just bad accounting.
You have free local models for most tasks, $20 subscriptions for near-frontier intelligence, and API per token costs for frontier intelligence.
Flash seems to be targeting the near-frontier category.
Open-source model inference providers (who do not have to bear the cost of training) seem able to do it at much lower prices.
https://www.together.ai/pricing
https://fireworks.ai/pricing#serverless-pricing (scroll down to headline models)
Of course, it's possible that they are burning through investor cash as well, and apples-to-apples comparisons are not possible because AFAIK Google does not mention the size/paramcount for 3.5 Flash.
But if the prevailing wisdom is true, I think it's actually encouraging. It suggests that OpenAI and Anthropic could perhaps, if they need to, achieve profitability if they slow down model development and focus on tooling etc. instead. If true that's probably good news for everybody w.r.t. preventing a bursting of this economic bubble.
...my opinions here are of course, conjecture built on top of conjecture....
I think you're right that releasing models at a slower cadence would bring down costs to some degree, but it's not clear how much. All of these companies could significantly reduce their opex but at the risk of falling behind in terms of being at the frontier.
The economic value increases non-linearly as models get more intelligent: being 10% more capable unlocks way more than 10% in downstream value.
That's trouble because the non-linear component means at some point their margins will stop primarily defined by the cost of compute, and start being dominated by how intelligent the model is.
At that point you can expect compute prices to skyrocket and free capacity to plummet, so even if you have a model that's "good enough", you can't afford to deploy it at scale.
(and in terms of timing, I think they're all well under the curve for pricing by economic value. Everyone is talking about Uber spending millions on tokens, but how much payroll did they pay while devs scrolled their phones and waited for CC to do their job?)
Qwen 3.6 hit hard in the self-hosting space. It's incredibly capable for its size, really shaking up what's possible in 64GB or even 32GB of VRAM.
The Prism Bonsai ternary model crams a tremendous amount of capability into 1.75GB.
And, DeepSeek V4 is crazy good for the price. They're charging flash model prices for their top-tier Pro model, which is competitive with the frontier of a few months ago.
The winners in the AI war will be the companies that figure out how to run them efficiently, not the ones that eke out a couple percent better performance on a benchmark while spending ten times as much on inference (though the capability has to be there, I think we're seeing that capability alone isn't a strong moat...there's enough competent competition to insure there's always at least a few options even at the very frontier of capability).
You can lower that to at least 24GB. I've been running Qwen 3.5 and 3.6 with codex on a 7900 XTX and the long horizon tasks it can handle successfully has been blowing my mind. I would seriously choose running my current local setup over (the SOTA models + ecosystem) of a year ago just based on how productive I can be.
DeepSeek V4 Pro likewise is insanely good for the price. I simply point it at large codebases, go get a cup of coffee or browse Hacker News, and then it's done useful work. This was simply not possible with other models without hitting budget problems.
This is what you get for relying on the generosity of billionaires. Keep offshoring your thinking ability to a machine and let me know how competitive you. Hint, you wont be. There's nothing special about being able to use an LLM.
Or if you prefer smaller ones, Qwen3.6-35B-A3B, https://huggingface.co/bartowski/Qwen_Qwen3.6-35B-A3B-GGUF
Of course not
And you don't need to
Is it? More capability, more demand, higher price. Seems relatively uninteresting. The naming structure complicates it: 3.5 Flash is less comparable to 3.0 Flash than it is to 3.0 Pro.
More generally, $/token + naming scheme comparisons are just confusing: I am not looking for a wordy idiot and I doubt most people are (at least not with what I would consider worthwhile business ambitions). In fact wordy idiots are fairly costly, because we have to consider the large amounts of cheap garbage that they are producing, and if you price your own time somewhat competitively then fairly quickly that's the bigger lever.
Even if we don't consider the last part: How do we price the better model, that can one shot a task without having to go back and forth and spending more tokens or having to fix more bugs later? It is definitely worth something and I think it's quite undervalued right now. What seems to be missing is a better measurement of capability per token. I don't know how that could look like. Maybe something like how we try and measure inflation, some basket of tasks (which then ends up being part of the training data so idk).
https://ai.google.dev/gemini-api/docs/models/gemini-3.5-flas...
3.1 flash lite isn’t quite as good as 3 flash preview (which is the most incredible cheap model… I really love it) — but 3.1 is half the price and the insane speed opens up different use cases.
For comparison, Opus models are $5/$25
Since Gemini 3.5 Flash is raising the price to $1.50/$9.00, it's priced between Haiku and Sonnet. If it outperforms Sonnet, it remains a good value, I guess. Though DeepSeek V4 Flash is much cheaper than all of them, and seemingly competitive.
Of course, if I manage to reach my limits every week on my Claude $200 sub, opus 4.7 is probably priced closer to flash!
Outside of coding, claude models are pretty meh. GPT and Gemini are the workhorses of science/math/finance.
I use it _a lot_ and it’s very capable if you just plan correctly. I actually almost exclusively use 3.1 flash lite and 2.5 flash lite (even cheaper) and we have 99.5% accuracy in what we do.
That said, I think we’ll see the lite/flash models and the pro models will diverge more price wise. The pro models will become more and more expensive.
Fwiw it’s beating Claude Sonnet in most benchmarking (benchmaxxing?), yet they’ve priced it almost half off on a per token basis.
Question is are you going to persuade anyone with this argument?
Are there many devs at Google who legit prefer Gemini over Claude and Codex? Would love to hear about that.
A few weeks ago, Steve Yegge claimed he'd heard that Google employees are banned from using Claude & Codex.
https://x.com/Steve_Yegge/status/2046260541912707471
A number of Googlers replied to say that was totally false, including Demis Hassabis, but they were all on the DeepMind team.
https://x.com/demishassabis/status/2043867486320222333
This person here claims they left Google because of the ban, and because the ban applied outside of Google work as well:
I think false (or hasn't filtered to everyone lol)
I will definitely not be updating to this new model, and I think once 2.5 Flash is deprecated I'll have to re-architect so Gemini is only used for web grounding requests. This is an insane price increase.
I think that they might have reached the latency sweetspot where voice applications become more natural. Natural speech is <100 tokens per second (after STT), so $9 for a million token takes you to roughly 3 hours of speech. That's totally competitive compared to human costs.
Inference alone is certainly profitable. I'm running models at home that are comparable to performance of paid models a year or so ago for free. Even for much larger models the cost around inference serving are clearly manageable.
Training is where the costs are, but I'm increasingly convinced those too could have costs dramatically reduced if necessary. Chinese companies like Moonshot.ai are doing fantastic work training frontier models for a fraction of the cost we're seeing from Anthropic/OpenAI.
This isn't like Uber or Doordash where the economics fundamentally don't make sense (referring to the early days of these services where rates were very cheap).
It's a compelling story that "current AI is unsustainable", but it doesn't pan out in practice for a multitude of reasons (not the least of which is that we can always fall back to what models did last year for basically free).
Profitable maybe, in terms of having low costs, but why pay Google or whoever when you can do it yourself for cheaper/"free"?
The small models are useful for small things like summarizing text or search but not much else.
Even anthropic who does not own any hardware still have a big margin providing claude models.
3.1 Pro did NOT find them. 3.5 flash did. Plus one I hadn't thought of that may or may not work (which it also pointed out).
I'm pretty impressed.
Empty Slot (new Pro as Mythos competitor?)
Old Pro -> now Flash
Old Flash -> now Flash Lite
Old Flash Lite -> now Gemma (and not served by Google)
I say "almost" because the situation is more fluid and unstable than a normal naming change. If Apple were to do this with laptops, maybe it'd be like, Air gets better and pricier and becomes Pro-level model, Neo same way becomes Air-level model, etc. But Apple's too design oriented to do something like that. Google, well...
This change has made me decide to move to a multi-provider situation like through OpenRouter for consumer-facing LLM api in a service I'm building. I just can't trust Google to not constantly rearrange everything under our feet. Doesn't mean I won't use Gemini, but it clearly means I need to have others in the mix ready to go. In fact I used to use lots of Flash Lite, which is now Gemma territory, and I can't get that served by Google anymore and don't want to run my own hardware.
But in any case, I'd compare this "Flash" model with previous "Pro" on all metrics. It's kinda like if in clothes a Small suddenly became what was a Large, or at Starbucks a Grande became the new de facto Venti. And only for the new! drinks.
And if we think this way, it's possible that prices are actually falling?
> which is now Gemma territory, and I can't get that served by Google anymore
Gemma is served by Google. They're serving Gemma 4 26B A4B at $0.15/$0.60.
https://console.cloud.google.com/agent-platform/publishers/g...
https://cloud.google.com/gemini-enterprise-agent-platform/ge...
and far cheaper than comparable models, Gemini Pro is cheaper than Claude Sonnet (Anthropic still gets to charge a brand premium)
I mean, the benchmarks for Gemini 3.5 Flash are very strong, but at those prices it has to be. I guess the time of subsidized tokens from the big guys is slowly coming to an end.
Maybe I'll look at Opus again, but it just was slower, much more expensive and worst at all - wasn't listening to you instructions.
Not the most intelligent but perfect balance of cheap, fast and not-too-dumb.
> Create animated SVG of a frog on a boat rowing through jungle river. Single page self contained HTML page with SVG
https://gistpreview.github.io/?5c9858fd2057e678b55d563d9bff0...
3.5 Flash: Thinking High - 7280 tokens
https://gistpreview.github.io/?1cab3d70064349d08cf5952cdc165...
3.1 Pro - 28,258 tokens
https://gistpreview.github.io/?6bf3da2f80487608b9525bce53018...
Though 3.1 took 3 minutes of thinking to generate, but it only one that got animated movement.
https://gistpreview.github.io/?3496285c5dac5ba10ebbc0b201a1a...
Gemini 2.5 Pro - 5,325 tokens:
https://gistpreview.github.io/?cc5e0fefeaaffecd228c16c95e736...
Gemini 2.5 Flash - 7,556 tokens:
https://gistpreview.github.io/?263d6058fe526a62b8f270f0620ec...
Gemma 4 31B IT - 3,261 tokens via AI Studio:
https://gistpreview.github.io/?858a42b96af864859a3b89508619d...
Gemma 4 26B A4B IT - 4,034 tokens via AI Studio:
https://gistpreview.github.io/?4adb7703897e0c6b583f9de928e4a...
https://gistpreview.github.io/?da742884e5e830ce71ee4db877519...
OFC this is just for fun, but nevertheless gave me working code on first try.
8112 tokens @ 52.97 TPS, 0.85s TTFT
https://gistpreview.github.io/?7bdefff99aca89d1bc12405323bd4...
Full session: https://gist.github.com/abtinf/7bdefff99aca89d1bc12405323bd4...
Generated with LM Studio on a Macbook Pro M2 Max
https://huggingface.co/hesamation/Qwen3.6-35B-A3B-Claude-4.6...
https://gistpreview.github.io/?557f979c82701862bc26d24f10399...
> Create animated SVG of a frog on a boat rowing through jungle river. Single page self contained HTML page with SVG. Use the Brave Browser to verifty that the image is indeed animated and looks like a proper rowing frog; iterate until you are satisfied with it.
It was able to discover and fix an animation bug, but the result is still far from perfect: https://gistpreview.github.io/?029df86d03bfe8f87df1e4d9ed2f6...
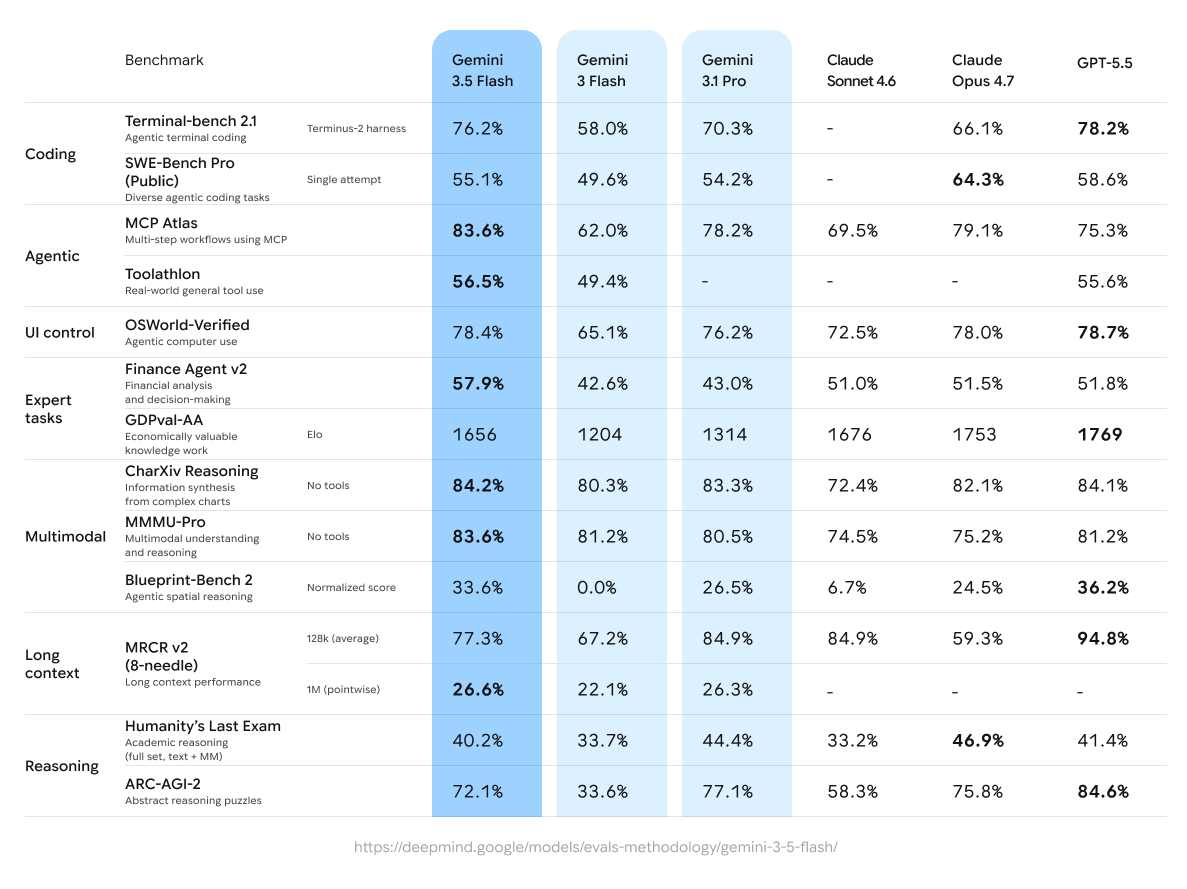
The benchmarks used don’t really give a full story
[1] https://github.com/htdt/godogen
[2] https://drive.google.com/file/d/1ozZmWcSwieZQG0muYjbj7Xjhhlz...
Now think, plan how to tell this story in a cartoon, make scene outline and then generate SVG animation story for "Three Little Pigs" in self contained HTML page. Just single animation no control buttons.
Actual results for models, one shot:
Gemini 3.5 Flash - Three Little Pigs - 9,050 tokens:
https://gistpreview.github.io/?ed9faa53604035005cae86c63c766...
Gemini 3.1 Pro - Three Little Pigs - 24,272 tokens:
https://gistpreview.github.io/?f506bbfd9b4459c8cd55d89605af8...
Gemini 3 Flash - Three Little Pigs - 5,350 tokens:
https://gistpreview.github.io/?f58eff069cf916031c97d560b0e35...
Gemma 4 31B IT - Three Little Pigs - 5,494 tokens:
https://gistpreview.github.io/?a3aa75abbe8fd7818b73f6fa55ee6...
Gemma 4 26B A4B IT - Three Iittle Pigs - 6,375 tokens:
https://gistpreview.github.io/?1e631caebeb54f9f0cd6d0e3d4d5e...
> Gemini 3.5 Flash’s pricing shifts the Pareto frontier in Text. 8 models from GoogleDeepMind dominate the Text Arena Pareto curve where only 4 labs are represented for top performance in their price tiers.
Artificial Analysis's "Cost to run" model (aka num_tokens_used * price_per_token) is much better, but even that is likely problematic since it's not clear whether running a bunch of benchmarks maps cleanly to real-world token use.
They continue to focus on smaller models while openai and anthropic are increasing compute requirements for their SOTA models.
They are just refining their current models while they finish training the next generation.
They will all come out at about the same time. Anthropic, OpenAi, Google, xAI
Hold on, I think this claim needs some hard data. Here you go gentlemen:
https://www.aisi.gov.uk/blog/our-evaluation-of-openais-gpt-5...
Can you link to a source?
For intelligence/size only OpenAI and Anthropic are the frontier. Google has more compute so it can compensate for that with size of the models...
Nobody really knows the answer to which one is more optimal
* Large model trained on a large amount of data across multiple domains, that doesn't need any extra content to answer questions.
* Smaller model that is smart enough to go fetch extra relevant content, and then operate on essentially "reformatting" the context into an answer.
It’s not possible to uptrain on preview releases and it did not get that much love for a while.
6x the price of 3.1 flash lite
Cost per task is a more productive measure, but obviously a more difficult one to benchmark.
Compare to the GPT-5.5 announcement: https://openai.com/index/introducing-gpt-5-5/
$0.15 / million tokens
$1.00 / 1,000,000 tokens per hour (storage price)
I confirmed this by running a bunch of prompts through Gemini 3.5 Flash without doing anything special to configure caching and noting that it comes back with a "cachedContentTokenCount" on many of the responses.
The "storage price" quoted is for an optional Gemini feature that most people don't care about: https://ai.google.dev/gemini-api/docs/caching#explicit-cachi...
And I guess Gemini 3.5 pro will have the pricing increment, too. 12 x 5 = 60?
It seems like google does want us to use Chinese models.
They are more willing to wait though, so Chinese models are pretty attractive right now.
Right question: What exactly is Google's plan for the long term pricing of these models, and are we all going to be priced out in a year?
That said, haste makes waste as the price point completely invalidates that
More often than not, people are using images in responses that go awry. Which is fair, the models are sold as multi-modal, but image analyses is still at gpt-4.0 text-analyses levels.
Also knowledge cutoff issues, where people forget the models exist months to a year or more in the past.
Claude also believes it knows how AWS' KMS works, quite confidently, while getting things wrong. I have a separate "this is how KMS replication actually works" file just to deal with its misconceptions.
For gemini, I typically use it to query information from large corpuses, but it often web searches and hallucinates instead of reading the actual corpus. On a book series, it will hallucinate chapters and events which, while reasonable and plausible, do not exist. "Go look at the files and see if your reference is correct" shows that it's not correct, and it's a mandatory step. But that doesn't prevent hallucination, but makes sure you catch it after the fact, just like a method in a class that doesn't exist gets found out by the compiler. The LLM still hallucinated it.
I was trying to understand a game I've been playing, The Last Spell. I asked it for a tier list of omens -- which ones the community considers most important. At least a few of the names it posts are hallucinated ("omen of the sun" does not exist, and the omens that give extra gold are "savings," "fortune," and "great wealth").
Obviously not a critical use case but issues like this do keep me on my toes regarding whether the thing is working at all. I should ask 3.5 flash to do the same job. (I did try and it once again hallucinated the omen names and some of the effects.)
The fix is easy enough though, a line in my global AGENTS.md instructing agents to search/ask for documentation before working on API integrations.
```
Build a Nango sync that stores Figma projects.
Integration ID: figma
Connection ID for dry run: my-figma-connection
Frequency: every hour
Metadata: team_id
Records: Project with id, name, last_modified
API reference: https://www.figma.com/developers/api#projects-endpoints
```
Note: You do need a Nango account and the Nango Skill installed before it could work.
Two of the three strip titles are hallucinated and two of the three strips are bad examples. Haley is mute in strip 403 and does nothing. Strip 578 is the start of the arc that shows the behavior Gemini is talking about, but has things going wrong so it's not a good example either.
Claude picks a good strip but also hallucinates the strip title: https://claude.ai/share/56be379d-c3da-443e-b60f-2d33c374eba8
...my chats are all pretty long and involve personal conversations, or I've deleted them. It's a lot to ask for someone to post receipts. The number of complaints is enough data.
No matter how big the model is there will be edge cases where it has no data or is out of date. In these cases it just makes stuff up. You can detect it yourself by looking for words like usually or often when it states facts, e.g. "the mall often has a Starbucks." I asked it about a Genshin Impact character released in June 2025 and it consistently interpreted the name (Aino) as my player character because Aino wasn't in its data.
Honestly I'm surprised your haven't encountered it if you're using it more than casually. Pro is much better but not perfect.
Also, prompts that reliably produce hallucinations is kind of a hard ask. It's inconsistent. One day the LLM I work with quotes verbatim from the PCIe spec and it's super helpful. The next day it gives me wrong information and when I ask it what section of the spec that information comes from it just makes up a section number
And when I say all the time, I mean it, and this is for Opus 4.7 Adaptive.
I often have to say, please do searches and cite sources, as if it doesn't it will confidently give me wrong or outdated information.
If you're often asking questions about a topic that's not in your specialist knowledge you won't notice them.
but for research it makes shit up all the time, I asked GPT5.5 to make me a build for Rogue Trader and not only did it use out of date info, it made up a bunch of skills that were NEVER in the game. I attribute that to there not being enough online information in the wikis or whatever but I wish it would just say "I dont know" instead of hallucinating but I know that's not how the tech works.
Coding, however, is solved like magic. Easier to add tests, to be fair.
AI psychosis would be the problem people talk about more, not just outright agreement but subtle ways of making you feel confident in your ideas. "yes, buy that domain name buy these other ones for defensibility"
(the domain name is dumb and completely unmarketable)
https://storage.googleapis.com/gweb-uniblog-publish-prod/ori...
If not then I’m not using it.
Cancelled my account 3 months ago, only Claude code level capability would bring me back.
For reference, this is a Rust codebase, deep "systems" stuff (database, compiler, virtual machine / language runtime)
They're still months behind OpenAI and Anthropic on coding.
Mind you I also find Claude Code careless and unreliable these days, too. (But it's good at tool use at least).
I do use Gemini for "lifestyle" AI usage (web research etc) tho.
I did not expect such a huge (3x) price increase from 3.0 Flash and I bet many people will not just blindly upgrade as the value proposition is widely different.
One interesting point to note is that Google marked the model as Stable in contrast to nearly everything else being perpetually set as Preview.
[0] https://artificialanalysis.ai/models/gemini-3-5-flash [1] https://artificialanalysis.ai/models/gemini-3-1-pro-preview
How many people complain that we have too much low quality AI output for humans to read, let alone evaluate vs. how many people are complaining that they want higher quality, more trustworthy output?
3.1 has 57M output tokens from Intelligence Index, 3.5 Flash has 73M, so not a lot more, and 3.5 is a bit cheaper, I don't get how 3.5 can be 74% more expensive.
That's everything I needed to know.
Does that mean this model is production ready?
Also concerned about Gemini models being benchmaxxed generally
I would say they are the least benchmaxxed out of all the top labs, for coding. They've always been behind opus/gpt-xhigh for agentic stuff (mostly because of poor tool use), but in raw coding tasks and ability to take a paper/blog/idea and implement it, they've been punching above their benchmarks ever since 2.5. I would still take 2.5 over all the "chinese model beats opus" if I could run that locally, tbh.
GDM is making (or has been backed into a corner into making) the bet that high throughput, low latency, low capability models are the path forward.
That probably works for vibe coded apps by non-practitioners.
I suspect that practitioners/professionals will wait longer for better results.
And Google is trying to make something affordable enough for a mass market, ad-supported audience.
They aren’t hyper focused on enterprise like Anthropic is. And that’s okay. There’s room for different players in different markets.
So, who is this for? People that want more ads and worse output, but want it faster? Sounds pretty awful to me.
This model isnt an advancement, its a previous model that runs more compute, which is why it costs more
Feels like the AI pricing noose is tightening sooner rather than later.
Plus the vibe of the gemini models are so weird particularly when it comes to tool calling
At this point I kinda need them to shock me to make the switch
Gemini 3.5 Flash: $0.75 input / $4.50 output per 1M tokens, 1M context window. The output price explicitly "includes thinking tokens" — which is why it's higher than a typical flash-class model.
For comparison within the Gemini lineup: - Gemini 2.5 Flash: $0.30 / $2.50 - Gemini 3.1 Flash-Lite: $0.25 / $1.50 - Gemini 3.1 Pro Preview: $2.00 / $12.00
So 3.5 Flash is ~2.5x more expensive input vs 2.5 Flash. The pricing and "including thinking tokens" framing position it as a reasoning-capable flash model rather than just a pure speed optimization.
If this is the big model release out of google, its a disappointent.
(I suspect you're viewing the "flex" pricing).
> The pricing and "including thinking tokens" framing position it as a reasoning-capable flash model rather than just a pure speed optimization
Every Gemini model starting with 2.5 has been a reasoning model.
{kind=link}