require('http').globalAgent.maxSockets = 64;
at the top of node script if you want a fair comparison with async php version. The bottleneck is bandwidth here. Not the runtime.
On my laptop, original script from the author took 35 seconds to complete.
With maxAgents = 64, it took 10 seconds.
Edit: And who is downvoting this? I just provided actual numbers and a way to reproduce them. If you don't like how the universe works, don't take it out on me.
There is a default connection pool of 5 requests.
If you have 5 or more extant http requests, any
additional requests will HANG for NO GOOD REASON.
> agent.maxSockets: By default set to 5. Determines how many concurrent sockets the agent can have open per host.
This stops you accidentally overloading a single host that you are scraping. It would not (assuming it works as described) affect your app if you are making requests to many hosts to collate data. Many applications (scrapers like httrack for instance) implement similar limits by default. If you are piling requests onto a single host but you either know the host is happy for you to do that (i.e. it is your own service or you have a relevant agreement) or have put measures in place yourself to not overload the target then by all means increase the connection limit.
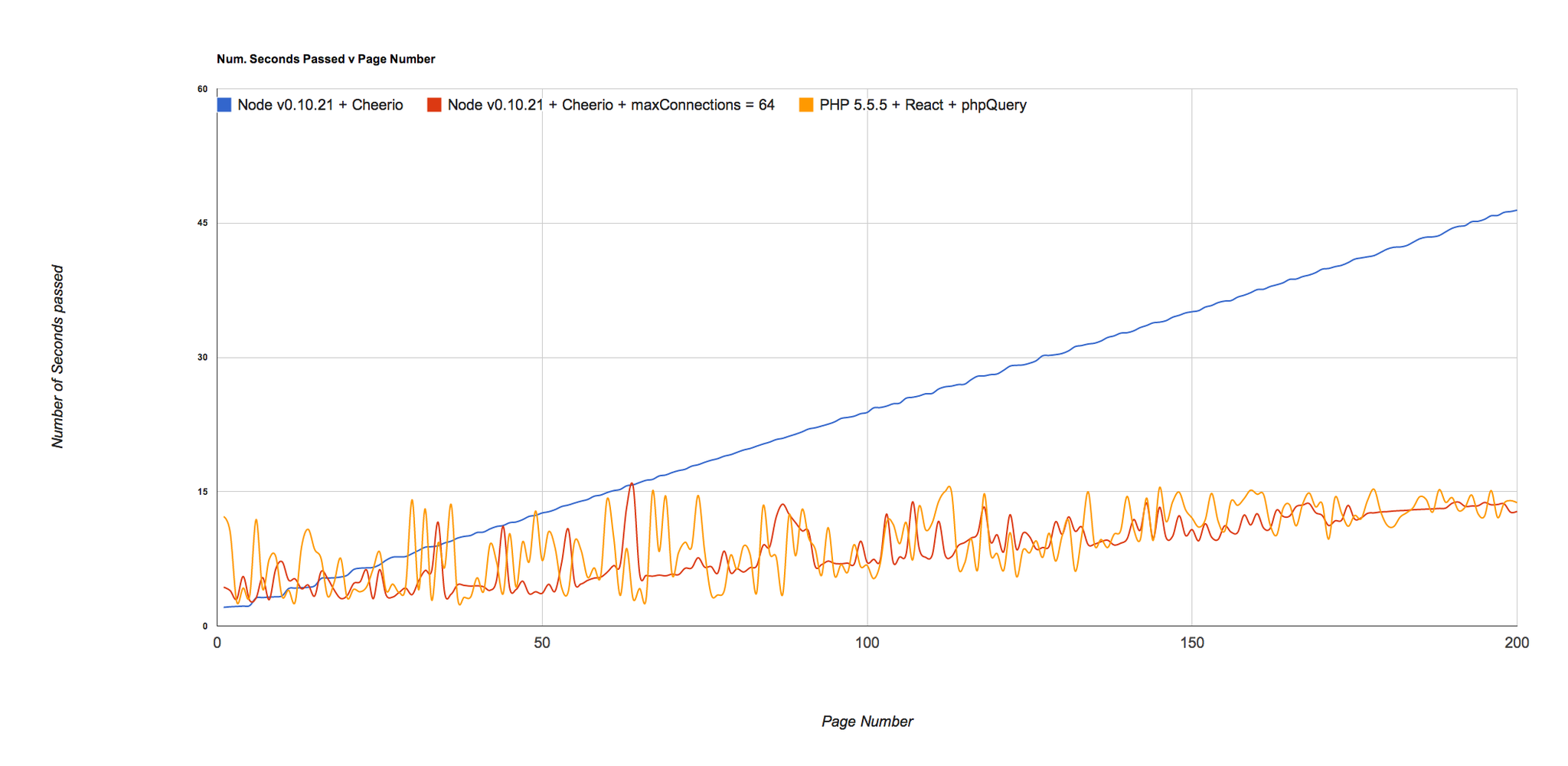
NodeJS v0.10.21 + Cheerio
real 0m47.986s user 0m7.252s sys 0m1.080s
NodeJS v0.10.21 + Cheerio + 64 connections
real 0m14.475s user 0m8.853s sys 0m1.696s
PHP 5.5.5 + ReactPHP + phpQuery
real 0m15.989s user 0m11.125s sys 0m1.668s
Considerably quicker! As I said I was sure NodeJS could go faster, but the point of the article was that PHP itself is not just magically 4 times slower, it is in fact almost identical when you use almost identical approaches. :)
> Update: A few people have mentioned that Node by default will use maxConnections of 5, but setting it higher would make NodeJS run much quicker. As I said, im sure NodeJS could go faster - I would never make assumptions about something I don't know much about - and the numbers reflect that suggestions. Removing the blocking PHP approach (because obviously it's slow as shit) and running just the other three scripts looks like this:
Also, that seems like a bit of a magic flag to add / tune, why is that not the default, and would I have to keep tuning it for each of my apps?
Neither the original benchmark nor the response were well researched IMO. This is the Apache vs IIS wars again, where good benchmarks that reveal useful information were drowned out by the noise of a great any poorly executed (or sometimes completely biased and deliberately poorly constructed), with bad test resulting in a bad result for one side being followed by an equally bad test to try prove the opposite.
Is this something safe to raise?
If so, just crank it up, should be safe unless you assign Infinity or something like that and push it too much (then you have another problem though). We use 15 in production where our server parses a lot of external web pages.
If you use it smart its safe enought
However you want to know what this benchmark proves? Absolutely nothing as it has to query a website. So the response time of the website matters more then this test.
The real trick here is async processing. A lot of the slow bits of PHP code is people not writing async data patterns.
If you use synchronous calls in PHP - mc::get or mysql or curl calls, then PHP absolutely sucks in performance.
Nodejs automatically trains you around this with a massive use of callbacks for everything. That is the canonical way to do things - while in PHP blocking single-threaded calls is what everyone uses.
The most satifying way to actually get PHP to perform well is to use async PHP with a Future result implementation. To be able to do a get() on a future result was the only sane way to mix async data flows with PHP.
For instance, I had a curl implementation which fetched multiple http requests in parallel and essentially lets the UI wait for each webservices call at the html block where it was needed.
https://github.com/zynga/zperfmon/blob/master/server/web_ui/...
There was a similar Memcache async implementation, particularly for the cache writebacks (memcache NOREPLY). Memcache multi-get calls to batch together key fetches and so on.
The real issue is that this is engineering work on top of the language instead of being built into the "one true way".
So often, I would have to dig in and rewrite massive chunks of PHP code to hide latencies and get near the absolute packet limits of the machines - getting closer to the ~3500 to 4000 requests per-second on a 16 core machine (sigh, all of that might be dead & bit-rotting now).
On the extension APIs
curl-multi - http://php.net/manual/en/function.curl-multi-select.php
memcached-getdelayed - http://us2.php.net/manual/en/memcached.getdelayed.php
mysqli-reap_async - http://us2.php.net/manual/en/mysqli.reap-async-query.php
postgres-send_query - http://www.php.net/manual/en/function.pg-send-query.php
gearman doBackground - http://www.php.net/manual/en/gearmanclient.dobackground.php
Something like gearman queues basically take the asynchronous processing out of the web layer into a different daemon. There were things like S3 uploads and fb API calls which were shoved into gearman tasks instead of holding up the web page.
Some of the stuff is very design oriented, for instance in most of my memcache code, there are no mc-lock calls at all - all of them are mc-cas calls. A lot of the atomicity is done by using add/delete/cas which involve no sleep timeouts. A bit of it was done using atomic append, increment and decrement as well.
SQL queries are another place where PHP doing actual work sucks for the web apps. A bunch of the mysql/postgresql functionality within a lock is actually moved onto stored procedures, instead of being driven by PHP.
https://github.com/zynga/zperfmon/blob/master/server/schemas...
So the code above is horribly written because you can't parameterize table names or column names in PL/SQL. But that essentially cuts down the involvement PHP has with the backend's locked sections.
Also a lot of the stats data was flooded onto apache log files instead of being written out from the PHP code directly using an fwrite.
https://github.com/zynga/zperfmon/blob/master/client/zperfmo...
This uses apache_note() function in PHP to log stuff after the request is done & the connections are closed. That gets into the log files as %(<name)n fields in the access log.
You can see there that every single access log has an associated user, the HMAC of the request and peak memory usage. All collected at zero latency to the actual HTTP call.
The thing to avoid though is pcntl - it absolutely messes up all of apache/fastcgi process management code.
This is not all of what I've done. I am sorry to say some of my best work in this hasn't been open-sourced & has perhaps been killed since I left Zynga.
PHP backends I built using these methods were handling approx ~6-7 million users a day on 9 web servers (well, we kept 16 running - 8 on each UPS).
Ah, fun times indeed - too bad I didn't make any real money out of all that.
1. Takes 1 minute to install on any platform (*nix, windows etc.)
2. A modern Package Manager (NPM) works seamlessly with all platforms.
3. All libraries started from 0 with async baked in from day 0.
4. No need to use any 3rd party JSON serialize/deserialize libs.
5. And above all, its Atwood's law
"any application that can be written in JavaScript, will eventually be written in JavaScript".
http://www.codinghorror.com/blog/2009/08/all-programming-is-...
1. apt-get install php5 ? Seriously, that's it. On the other hand, neither Debian stable nor Ubuntu LTS have any usable version of node in their package repository (Debian has nothing, Ubuntu has 0.6)
4. json_decode() ?
5. If Atwood's law ever becomes reality, it will be a consequence, not a source of benefit.
(I don't use either Node or PHP as my main language)
NodeJS literally takes 5 minutes to get started writing scalable apps without even thinking about concurency at all.
Write a software in Php yourself and let people download and run themselves, there are endless pain. Actually Php sucks in many areas which I dont want to touch right now.
1. You have to be kidding, right? PHP's popularity is precisely because of this.
2. getcomposer.org
4. json_decode/json_encode have been a part of PHP since PHP 5.2 (2006)
5. That's not a benefit.
Composer is terrible compared to NPM.
1. My recent installs of node have required compiling from source to get anything remotely up-to-date, however there are packages for both,
2. Composer with the Packagist registry is comparable here - you might be thinking of PEAR.
3. JS certainly has much better async support - it being JavaScript after all.
4. PHP has JSON encoding/decoding bundled, no third party lib required.
5. For better or worse
I'd trade decent JSON support for decent XML support every single day of the week.
And Scala/Java/JVM have already solved the problems you mention above.
Just out of interest, why is that?
I work with JSON at least once a week, but it can be months between moments when I need to work with any XML.
What is it you think is missing XML-wise in Node.js?
2. Whatever we're saying here includes only NodeJS vs PHP.
For example:
for($i = 0; $i < count($list); $i++)
$count = count($list);
for($i = 0; $i < $count; $i++)
That is, one could argue that a good language is one that lets developers ignore trivial changes like this without hurting performance.
A function call in a loop condition might have side effects or do something very unorthodox.
At some point, you'd expect these arbitrary this vs. that comparisons to die off. They haven't, and I'm guessing they won't.
Basically, it comes down to picking the tool that best supports your use case, or being okay with a compromise. Like the SQL/NoSQL discussions recently... Use it poorly and you get poor results.
But the reason for this wasn't that Node/JS is faster than PHP; it was because I was able to write the Node.js app asynchronously, but the PHP version was making hundreds of synchronous requests (this is the gist of the OP).
The issue I have is that Node.js makes asynchronous http calls relatively easy, whereas in PHP, using curl_multi_exec is kludgy, and few libraries support asynchronous requests.
The situation is changing, but the fact remains that asynchronous code is the norm in Node.js, while blocking code is the norm in PHP. This makes it more difficult (as of this writing) to do any non-trivial asynchronous work in PHP.
I am really enjoying reading Go code and seeing how people use concurrency etc; and they are all doing it the same. When I would read ruby, I would have to know the particulars of a library like Celluloid or EventMachine which made it harder.
One funny thing is that the ReactPHP[1] site is visually similar to the Node[2] homepage.
[1] - http://reactphp.org/ [2] - http://nodejs.org/
A lot of the components are in production already, it was built by the original developers to be used in production. It's on 0.3.0 for many parts, which is no further behind where Node was when people started flapping about it :)
Scraping using jQuery syntax such as:
$('table tr').each(function(ix, el) {
names .push($(el).find('td').eq(0));
surnames.push($(el).find('td').eq(1));
})
Even if Node was 5x slower than PHP I would still go for Node because of its easy jQuery syntax.
* cheerio (https://github.com/MatthewMueller/cheerio)
* PhpQuery (https://code.google.com/p/phpquery/wiki/jQueryPortingState)
Both of these use a jQuery-esque syntax, so your comment regarding DOM traversal in PHP is a moot point.
When you are scraping it's great to be able to do a test run in the browser console and then just paste the code into your node script without any language porting.
It's not an argument that it's better or faster or anything than PHP, just that some find it easier to hack a scraper together in this way.
That "jQuery syntax" has nothing to do with the language itself. jQuery uses Sizzle[0], which is a CSS selector library for JavaScript. There are plenty of PHP libraries which provide CSS selectors, such as the Symfony CssSelector component[1].
http://symfony.com/doc/current/components/dom_crawler.html#n...
{kind=link}
{kind=link}