> Why so angry? I know I’ve taken this far too personally. I have no illusions that everything I read online should be correct, or about people’s susceptibility to a strong rhetoric cleverly bashing conventional science, even in great communities such as HN. But frankly, for the last few years, the world seems to be accelerating the rate at which it’s going crazy, and it feels to me a lot of that is related to people’s distrust in science (and statistics in particular). Something about the way the author conveniently swapped “purely random” with “null hypothesis” (when it’s inappropriate!) and happily went on to call the authors “unskilled and unaware of it”, and about the ease with which people jumped on to the “lies, damned lies, statistics” wagon but were very stubborn about getting off, got to me. Deeply. I couldn’t let this go.
I am afraid I actually agree with the author's point. The anti-intellectual, anti-scientific streak in many poor analyses claiming to debunk some scientific research is deeply concerning in our society. If someone is trying to debunk some scientific research, at least he should learn some basic analytic tools. This observation is independent of whether the original DK paper could have been better.
That said, I give the benefit of doubt to the author of "The DK Effect is Autocorrelation." It is a human error to be overly zealous in some opinions without thinking it through.
There is no pat "trust science more" or "trust amateurs less" answer here. The actual answer is that if you want to understand research, you need to actually understand mathematical statistics and the philosophy of statistics fairly deeply. There just isn't any way around it.
1. https://journals.plos.org/plosmedicine/article?id=10.1371/jo...
On the other end there's distrust of broad scientific consensus across different professions, countries, etc. It's the distrust at these levels that is the increasing problem we are facing today.
It's more than that, I think. Sibling-thread poster hit the nail on the head when he complained of politicised science.
The social sciences have this dominating and silencing effect on the rest of the sciences.
There's always been junk science, and when found out it gets discredited. This is still happening and is a good thing.
What's new is that any research that might produce results counter to the what the PC-mob deems acceptable is attacked. Whether or not there is consensus amongst researchers in that field is irrelevant when the mob calls for the firing of any researcher who doesn't toe the current political party-line.
Sure, we're not actually in the dark ages, but a trend of silencing voices in the name of purity of thought is particularly troubling, especially as the mob asking for this is unashamedly attempting to implement NewsSpeak[1].
[1] See the argument in yesterdays threads about what "man" and "woman" mean, and should dictionaries be changed, etc.
A problem here is that there are fields of science that are almost certainly bogus in themselves. One very likely candidate is nutrition, which seems to be fumbling in the dark and has a long history of producing worse recommendations than doing nothing (e.g. replace fat with sugar). More controversially, the entire field of economics is seen by some to be very suspect from a basic foundations view.
Put simply, science is advertised as self-correcting but in reality it's not. Representative experience documented here: http://crystalprisonzone.blogspot.com/2021/01/i-tried-to-rep...
So, the reasons people learn a generalized distrust of science are that often the sausage doesn't get made. Bad science is published, applauded, cited, breathlessly covered in the media and may even be replicated, yet the first time outsiders to the field actually read the paper they realize it's nonsensical. But then they realize nobody cares because careers were made through this stuff, so why would anyone inside the field want to unmake them?
The degrading trust doesn't come from bad results per se, but rather the frequent lack of any followup combined with the lack of any institutional mechanisms to detect these problems in the first place beyond peer review, which is presented as a gold standard but is in no way adequate as such.
For example, consider how programmers use peer review. We use it, and we use lots of other tools too because peer review is hardly enough on its own to ensure quality. Now imagine you stumbled into a software company that held a cast-iron policy that because patches get reviewed by coworkers you simply don't need a test suite, nor manual testing, nor a bug tracker, code comments, security processes, strong typing, etc. And their promotion process is simply to make a ranking of developers by commit count and promote the top 10% every quarter, and fire the bottom 10%. Moreover they thought you were nuts for suggesting that there was any problem with this. You'd probably want to get out of there pretty fast, but, that's pretty much how (academic) science operates. So of course this degrades trust.
Who says there is anyone who can be trusted? People keep looking for leaders they can trust and it takes only a brief look at history to see that the search won't stop despite the jaw dropping futility of the exercise.
The important thing is to check that people have incentives to tell the truth and no conflicts of interest. I'd trust someone untrustworthy if they were making money off my well-being. The only thing to watch out for is them not being forthright about their incentives.
We shouldn't trust that skyscrapers stay up because engineers are trustworthy. They stay up because the engineer goes down with the building.
Plus, it would reduce the number of publishable papers quite substantially including from high profile authors/groups, so I don't think they want the fight. We should also remember that most journal editors are also involved in publishing this research — they often have no real incentives to make things awkward.
That's a very simplistic take on it. Bad science is a necessary part of the process and dealt with accordingly by the scientific method.
The problem is that science that is bad or incomplete is being reported as fact or truth, or arguably even worse, as entertainment in order to gain an audience. This is what actually eroded the trust in science, as people kept repeating things that reinforced and further misshaped their biases.
Human nature tends to distrust stuff we don't understand. Hence, our trust in science, which in many fields is often beyond the understanding of laymen, have to have constant reinforcement. However, the goal of media, and especially social media is to increase eyeballs for their content, and the truth sells a lot less well than sensationalised content pandering to the audience.
Simply put, there is not much profit in reporting science truthfully, and every incentive to sensationalise it.
A theory ought to be able to answer questions like “Why don’t train engineers take the curvature of the Earth into account?”
The problem is when someone comes along and thinks an unanswered question (or even just someone not knowing the answer off the top of their head) proves a theory is completely false (or worse, proves their favorite theory correct). (And to even believe the Earth is flat is to be a conspiracy theorist so in this particular case no prove will ever suffice anyway.)
In between us (gen pop) and The Method are scientists, and scientists are just as fallible as any other group of people - lawyers, politicians, coders, shop assistants.
Alas, that's a hard sell to laypersons thru the mediums of soundbites and tweets.
I recall one study that said all white people are committing environmental racism against all non-white people. I dove in and read the whole thing wondering what method could have yielded scientific confidence in such a broad result. Turns out the model used was a semi-black box that required a request for access and a supercomputer to run. But it was in a Peer Reviewed Scientific Journal and had lots of Graduate Level Statistics so I guess it seemed trustworthy.
It is literally like this:
- someone makes a point that questions your believe
- you google a phrase that would come in studies that proof otherwise
- you take the first thing that looks promising, and fly over the first page, and paraphrase a good bit in a way that makes your point
- you publish it as part of a post, youtube video or whatever
- danger averted
Bad studies play into this, but even if the studies are good, or bad studies that have been retracted the same thing happens. James Wakefield who originally published the "combined vaccines cause autism study" after patenting a non-combined measles vaccine had his study retracted by the lancet soon after publication. He lost his status as a doctor etc. And you will still find people who use his study as a source.
Of course studies whose outcome collide with our believe systems are always harder to trust than those who validate it — but this is why you look at the methods used and other indicators that might make that study bogus.
I don't think this is true. It is possible to put a lot of work into unsound statistics and to make a lot of "noise and fury" about how mathematical you are while failing some basic principle, but I don't think sound statistics can mislead. The replication crisis was caused by scientists not being rigorous and journals not forcing them to be. You absolutely cannot accept publication as a sign of sound techniques except in journal/field combinations that have a deserved reputation.
Of course they can, unless you magically exclude all statistics that made a bad assumption on independence.
I plot all the daily high temperatures and the presence of the ice cream cart and it turns out the ice cream cart causes warmer highs! Solid statistics.
Turns out the guy that has the ice cream cart has a weather app on his phone though and doesn’t come out on forecasted cold days.
The book "How to lie with statistics" is one of the best statistics textbooks that I have read. It basically makes you immune to misleading stats (charts, tables, everything).
IIRC, the only thing that is missing from the book (it's a really old book) which is very relevant is p-hacking.
If only there were a term for "a cognitive bias whereby people with limited knowledge or competence in a given intellectual or social domain greatly overestimate their own knowledge or competence in that domain relative to objective criteria or to the performance of their peers or of people in general"
What billionaire funds “contrarian” research?
Anyway, "The DK Effect is Autocorrelation" definitely seems to be both statistically literate, and a good faith criticism of the Dunning-Kruger paper. In light of that, calling it "anti-scientific" seems unfair, since criticism and debate are an important part of science.
It does affect your conclusions though.
The choice of null hypothesis in "The DK Effect is Autocorrelation" determined how the random data was generated. The hypothesis is: "nobody has any clue whatsoever how competent they are". The random data was specifically crafted for that hypothesis.
The choice of null hypothesis in this article is: "everyone roughly knows how competent they are". This random data, too, is specifically crafted for the null hypothesis.
So what does this mean? If you pick the a particular null hypothesis then you can try to argue that the DK is a statistical artefact. But it's not, it is an artefact of choosing a particular null hypothesis.
There are valid criticisms of the DK study, though. See this comment for example: https://news.ycombinator.com/item?id=31119196
> the p-value is a strongly nonlinear transformation of data that is interpretable only under the null hypothesis, yet the usual purpose of the p-value in practice is to reject the null. My criticism here is not merely semantic or a clever tongue-twister or a “howler” (as Deborah Mayo would say); it’s real. In settings where the null hypothesis is not a live option, the p-value does not map to anything relevant.
https://statmodeling.stat.columbia.edu/2017/01/07/we-fiddle-...
Behavioural science is a pretty new field, its pretty easy to get abberant results or manipulate the results to show 'something' statistically. Many findings in earlier papers could not be replicated, or had applied statistics incorrectly, or showed different results when research participants were not white college kids.
This is a whole other problem within academia, the pressure to publish something even when there is nothing and perceived legitimacy based on the number of citations a paper has. My professor always said don't look at the number of citations, understand the method and the rebuttal, there were numerous low citation but solid papers showing flaws in famous ones but everyone who isn't deep into the subject holds the original assertion to be legitimate because its "famous"
People endlessly reference the Dunning-Kruger effect as a meme, without ever having read the paper, let alone having checked its methods. You don't seem to have a problem with that.
On the other hand, after seeing an article that uses essentially statistical arguments to debate a scientific study you conclude that there is some "anti-intellectual, anti-scientific streak" in our society and that it should be of grave concern.
This doesn't make any sense except as an extreme case of virtue-signaling.
What's more harmful to medicine: a fashionably non-expert contrarian who doesn't understand the appropriate null hypothesis making a superficially plausible statistical argument that actually the trials suggest the drug is harmful to wide acclaim from laymen, or people casually referencing or even being administered the drug without reading the original trial writeups for themselves?
Everyone is free to question the results, but after actually reading the entire paper I can confidently say that poking a bit at the correlation in the charts falls way short of undermining the actual findings from the paper. The actual results are much more detailed and nuanced than two straight lines at an angle.
[1] https://www.researchgate.net/publication/12688660_Unskilled_...
1. It uses a tiny sample size.
2. It assumes American psych undergrads are representative of the entire human race.
3. It uses stupid and incredibly subjective tests, then combines that with cherry picking:
"Thus, in Study 1 we presented participants with a series of jokes and asked them to rate the humor of each one. We then compared their ratings with those provided by a panel of experts, namely, professional comedians who make their living by recognizing what is funny and reporting it to their audiences. By comparing each participant's ratings with those of our expert panel, we could roughly assess participants' ability to spot humor ... we wanted to discover whether those who did poorly on our measure would recognize the low quality of their performance. Would they recognize it or would they be unaware?"
In other words, if you like the same humor as professors and their hand-picked "joke experts" then you will be assessed as "competent". If you don't, then you will be assessed as "incompetent".
Of course, we can already guess what happened next - their hand picked experts didn't agree on which of their hand picked jokes were funny. No problem. Rather than realize this is evidence their study design is maybe not reliable they just tossed the outliers:
"Although the ratings provided by the eight comedians were moderately reliable (a = .72), an analysis of interrater correlations found that one (and only one) comedian's ratings failed to correlate positively with the others (mean r = -.09). We thus excluded this comedian's ratings in our calculation of the humor value of each joke"
The fact that this actually made it into their study at all, that peer reviewers didn't immediately reject it, and that the Dunning-Krueger effect became famous, is a great example of why people don't or shouldn't take the social sciences seriously.
Oh the irony in your last statement. Somebody who hasn't done social science research professionally (this is an assumption, let me know if I'm wrong), has difficulty judging what social science research can (and can't) do ...
I’d we take your claim seriously then we have to disallow all critiques of the replicatability crisis in the social sciences that don’t come from social scientists, but that would present an obvious new problem: conflict of interest. It’s also just an absurd requirement.
Let's look at the second test. It's advertised as a "logic test". The description is:
> Participants then completed a 20-item logical reasoning test that we created using questions taken from a Law School Admissions Test (LSAT) test preparation guide (Orton, 1993).
That's the entire description of their method. So immediately, we can see the following problems:
1. Just like the joke test, there's no way to replicate this given the description in the paper. Which questions did they take and why? In turn this throws all claims that the DK study has been replicated into question.
2. The citation is literally a Cliffs Notes exercise for students. It's about memorization of answers to pass law exams, not an actual test itself designed to verify logical reasoning ability. Why do they think this is a good source of questions for testing logic? Law is not a system of logic, there's even a famous saying about that: "the life of the law is not logic but experience". If you wanted to test logical reasoning a more standard approach would be something like Raven's Matrices.
Putting my two posts together there's a third problem:
3. Putting aside the obvious problems with subjectivity, their joke test is defined in an illogical way. They define a test of expertise (working as a comedian), select some people who pass this test and define them as experts, then discover that one expert would have been ranked by their own test as "incompetent but doesn't know it". Yet this is a contradiction, because this person was selected specifically because the researchers defined them as competent. Rather than deal with this logical contradiction by reframing the question they simply ignore it by discarding that comedian from their expert pool.
This is good evidence that DK themselves weren't particularly logical people, yet, they claim to have designed a test of logic - a bold claim at the best of times. Ironically, it appears DK may be suffering from their own effect. They believe themselves to be competent at designing tests yet the evidence in their paper suggests they aren't.
Full disclaimer - I was a sociological researcher before I started working in IT - and would (I can appreciate the irony given all of this is about DK effect) rate myself as very significantly above average in terms of methodological rigour and mathematical skill compared to other social researchers.
One thing that is taught to social researchers - although I've seen it much less with psychologists - is that social research is fundamentally different from natural sciences in that it is accepted as fundamentally subjective. Now, a radical such as myself will tell you that all research, including natural science, is not entirely objective due to very subjective navigation of selection bias, but putting that to the side - this is an extremely important point when evaluating social research.
Coming back to your original point - I would agree with the points you object to vis-a-vis original DK Effect paper, however, as a social researcher, I am always already coming into reading that paper knowing that I'll have to take it with spoonfulls of salt. There is no need to write the paper in a way that puts in many of the disclaimers you might expect, because we are institutionally taught that these disclaimers apply.
Having said that - one of my peeves with social research, and why I ultimately went away, is that a lot of garbage goes on and gets through peer review. There is almost no proper testing of quantitative instruments and methods. Which is why I agree with your point that it rightfully isn't taken seriously - but I would object to your assertion that it shouldn't be taken seriously. Especially amongst IT professionals who are already going to have a bias against non-STEM. Point out the shortcomings and apply a different interpretive lense, rather than discounting the field completely - as social science can be better and taken seriously if it was held to a higher standard, even with the methodological shortcomings we have today - but it is very often discounted wholesale, which I don't think is going to incentivise the bubble that is forming around it to reform and get better.
So it seems people are bad at doing global rankings. If I tried to rank myself amongst all programmers worldwide, that seems really hard and I could see myself picking some "safe" above-average value just because I don't know that many other people.
There's also: If you take 1 class in piano 30 years ago and can only play 1 simple song, that might put you in the 90th percentile worldwide just because most people can't play at all. But you might be at the 10th percentile amongst people who've taken at least 1 class. So doing a global ranking can be very difficult if you aren't exactly sure what the denominator set looks like.
So I think it's an artifact of using "ranking" as an axis. If the metric was, "predict the percentage of questions you got correct" vs. "predict your ranking", maybe people would be more accurate because it wouldn't involve estimating the denominator set.
Yes, and this literally implies that people in the lowest quartiles can't and won't rate themselves to be in the lowest quartiles when they are forced to give an answer. (Especially on tests that doesn't measure anything (getting jokes? really?), on tests that they have no knowledge about (how would they know that how their classmates perform on an IQ test???), or on tests that just have a high variance.)
And therefore they will "overestimate their performance".
It's like grouping a bunch of random people, and forcing them to answer whether their house is short, average or high. The "people living in short houses" will "overestimate the height of their houses", while the "people living in towers" will humbly say they live in an average high house.
Is this an existing and relevant psychological phenomenon, different from the general inability to guess unknown things? I don't think so.
If you think so, then give me proof.
> how would they know that how their classmates perform on an IQ test???
Are you serious? If you're interacting with your classmates, you definitely should have some idea on how their intellectual capabilities differ between each other and also with respect to you. In a small class doing lots of things together, someone might even literally count their "ranking" at some metric that highly correlates with IQ, estimating that Bob, Jane and Mary are above me and Dan and Juliet are below me, so I'm at 40th percentile.
It's not appropriate to treat these aspects as unknown things or unknowable things.
1) self-assessment is perfectly correlated with skill, or
2) completely uncorrelated.
I think neither of these makes sense as a null hypothesis.
The model you describe matches my intuition about what we should expect: people know something about their own skill level, but not everything.
And this is a true dichotomy. The "autocorrelative" effect doesn't need perfect correlation, just some correlation.
When you learn something you also learn what are some of the mistakes you can make. You evaluate your performance then against the mistakes you didn't make. Consider a piano player, or figure-skater. You have to know about what figures are difficult to perform to evaluate a performance, and you don't know what the difficult ones are until you have studied and tried to perform them.
It’s been argued before that this is the only reason that DK gained any notoriety; because it feels right, not because it is right. It’s the “just-world” theory: we want to believe that confident people are overcompensating.
Is it actually intuitive though? Consider your own example. Most people who don’t know piano or figure skating are well aware that they don’t know, and do not rate themselves highly at all. Would it be surprising to learn that people who don’t know any law or engineering don’t often hold any doubts about their lack of skill, and by and large are not deluded nor erroneously believe they’re great at these things they don’t know?
The DK paper didn’t measure knowledge-based skills like piano, figure skating, or law. It measured things like the ability to get a joke, and conversational grammar. How would you rate your own ability to get a joke? (Does this question really even make a lot of sense?)
It’s important that the methods in the DK paper focused on tasks that are hard to self-evaluate, because when people have tried to replicate DK with more well defined knowledge-based activities, they have often demonstrated the complete opposite effect, that there is widespread impostor syndrome, and skilled people underestimate themselves.
I think this case (real_skill = 0, perceived_skill = 0) is maybe a trivial case, and that the bit of truth DK-idea catches is when someone with very little skill considers how much work it would be to get to whatever a 'fully skilled' version would be, they woefully underestimate.
Picture someone in their first summer of mountain biking watching youtube videos of the best guys. Yes, you know you can't jump like they do, or turn as skillfully, but you're getting better each month. However, you still grossly underestimate how hard it is to get to that skill level.
At least it's my personal experience as a thoroughly unskilled!
I'm sorry, but I have to comment on a word in this line: I feel that increasingly, "notoriety" is used when "notability" might be better.
A thief is notorious. A statistical effect is notable, imho.
But I agree with your basic point: I can't skate, much less figure skate. And I am pretty accurately aware of that fact despite my lack of skill.
Thinking about all the "INAL" answers and the obviously wrong "legal" advice and opinion on legal topics you can come across on HN on a daily basis, I think law is good example of people overestimating their knowledge.
Replace figure skating with any other sports, so, and try having discussions about, e.g, a defeat of any soccer team. All of a sudden everyone just became a soccer coach. And everyone is able to critique individual player's performance and skill and technique. If anything, this proofs the DK effect rather well.
There are people who can't advance because they can't see the problem, and people who can't advance because they can't (or don't want to) correct it. The end result is the same though.
Conversely it cannot also be under zero, so error is most likely going to be above the actual skill line (over estimation, since it's clamped below it).
If you had never listened to a professional play piano before then you'd have no idea what level of performance is possible. Similarly, if you had never seen skilled skaters perform on TV.
But we have done these things, so it's obvious that they're doing something that's very difficult.
Maybe you don't fully appreciate the skill, though. You wouldn't do well as a judge who compares the performances of professionals. But comparing novices to professionals seems easy?
But we have done these things, so it's obvious that they're doing something that's very difficult.
Sometimes the things we find most impressive, in a demonstration of a skill we don't have, aren't the most difficult things.
I remember being absolutely blown away by some aerial circus tricks and stunts I saw at shows. Later, I started studying and eventually performing myself, and it's often the case that the most crowd-pleasing stunts are some of the easiest to perform.
As a performer, you could always tell which members of the audience knew their stuff, because they'd be the only ones applauding the tricks that might not have looked so spectacular, but were actually the most difficult.
Taking the piano example: after 1-2 years of progressive learning you can certainly give off the impression to somebody unfamiliar/untrained (including yourself to an extent) that you are actually quite good: Intermediate stage. But after awhile when confronted with more and more challenging stuff, by discovering different styles and finetuning your hearing; you at some point reach the very visceral and uncanny sensation of the countless possible roads you can now explore: advanced stage.
then, as a person who has lived in the world and has the normal physical skills of such you probably think "whoa, how in the heck did they do that" when you finally see it.
"And maybe there’s no contradiction - there’s always room for nuance, for finding out where the Dunning-Kruger effect is relevant and where it’s not. That can be done with more studies, but only if the authors manage to agree on assumptions and basic statistical practice."
I linked to the start of the video where he begins to build the idea. TLDR is he mentions Monet painting Impression Sunrise and how it was something that people have never seen before and it took a bit of time for it to blow people away--they needed to develop "new eyes" to see the genius. Adam then dives into this idea of "new eyes". I'm sure many of us have experienced this in our life and it was so nice to hear Adam unpack it.
> After two months in the bakery, you learned how to “see” clean.
> Code is the same way.
[1] https://www.joelonsoftware.com/2005/05/11/making-wrong-code-...
> OK, so far I’ve mentioned three levels of achievement as a programmer:
> 1. You don’t know clean from unclean.
> 2. You have a superficial idea of cleanliness, mostly at the level of conformance to coding conventions.
> 3. You start to smell subtle hints of uncleanliness beneath the surface and they bug you enough to reach out and fix the code.
> There’s an even higher level, though, which is what I really want to talk about:
> 4. You deliberately architect your code in such a way that your nose for uncleanliness makes your code more likely to be correct.
> This is the real art: making robust code by literally inventing conventions that make errors stand out on the screen.
If human cultures can be characterized as default arrogant or default humble then it stands to reason that arrogant cultures will have a DK effect, and in humble cultures you won't.
There is also the other end of the scale where "skilled and unaware" occurs: people under-assessing their skill (presumed that this is due to judging that most people also have similarly high skill levels).
I think your two "cultures" would shift the self-assessment line up or down on the graph (constant), but not affect the slope very much (multiplier). The line shape or line slope must change somewhat since values are limited (between 0 and 100).
When I did some cognitive behaviour therapy, I un-learned things like "all or nothing thinking" and the expectation that I could accurately predict the outcome of any course of action by modeling future performance off of a past failure.
Do you know any words, stereotypes, or clichés for this? Or even what the related mental disorder is called if it were to become debilitating? Or a specific word for the complete clustering of related signals?
I am guessing those issues plus there related issues (¿syndromic?) are common - but I don’t know where to group it in my own mind.
A large portion of the HN audience really, really wants to think they're smarter than mostly everyone else, including most experts. Very few are. I'm certainly not.
Articles which "debunk" some commonly held belief, especially those wrapped in what appears to be an understandable, logical, followable argument, are going to be cat nip here.
Articles like this are even stronger cat nip. If a member of the HN audience wants to believe they're mostly smarter than mostly everyone else, that includes other members of the HN audience.
So, whenever I read an article and come away thinking that, having read the article, I'm suddenly smarter than a huge number of experts, especially if, like the original article, it's because I understand "this one simple trick!", I immediately discard that knowledge and forget I read it.
If the article is right, it will be debated and I'll see more articles about it, and it'll generate sufficient echoes in the right caves of the right experts. Once it does, I can change my view then.
I am not a statistician, or a research scientist. I have no idea which author is right. But, my spider sense says that if dozens of scientific papers, written by dozens of people who are, failed to notice their "effect" was just some mathematical oddity, that'd be pretty incredible.
And incredible things require incredible evidence. And a blog post rarely, if ever, meets that standard.
It's not that at all. The assumption should be that everyone is equally good (or bad) at assessing their performance. Not that they have no ability but that the means between groups is the same vs. not the same. That the ability to assess themselves is independent of performance.
Say that everyone is equally okay at assessing themselves, and get within 0.1 of their actual performance (rated from 0 to 1). Then X and Y are going to be very correlated, as X - 0.1 < Y < X + 0.1. But X-Y will look like a random plot, since Y is randomly sampled around X.
The only case where X and Y wouldn't correlate at all is if people have no ability to assess their performance (IE, Y isn't sampled around X, but is instead sampled from a fixed range).
The less you know, the more random your guess at your own knowledge is. The actual value is low and less than zero isn't an option, so this drags the average up consistently.
The more you know, the more accurate your guess of your knowledge is. Especially as you hit the limits of the test, this noise can only drag the average down, but less dramatically than the other case.
With the reasonable conclusion: We all suck at guessing how much we know, but the more you know the less you suck until you hit the limits of the framework you are using for quantization of knowledge.
There are ways to fix this:
- Throw out the extreme high and low ends of the data bc the model breaks down there. (Which results in a very boring result)
- Have people guess their score and a rough level of confidence along side it (just a 0-5 sort of thing) and see what happens.
Note that I actually do think from my own experience that the effect is real, but the arguments presented fail to prove it statistically bc the model breaks down at the extreme where the effect is detected.
I’m not a statistician but I do have some basic training in psychometrics. It might be interesting/helpful to point out that your priors about self-assessment seem more reasonable generally but also put a lot of faith in the test’s validity as a measure of skill.
I’m relying on intuition here, but it seems a little problematic that the actual score and the predicted score are both bound to the same measurement scheme. Given that constraint on some level we’re not really talking about an external construct of skill, just test performance and whether people estimate it well. Which is different from estimating their skill well.
Maybe someone with more actual skill can elaborate or correct haha.
It serves mostly as a way of reassuring themselves of their own superiority. The message (for them) basically amounts to "other people's claim to knowledge is just further proof that they don't know anything."
I feel like I’m honestly yet to see somebody make DK accusations in a way that’s not totally cringe.
I recall that either Dunning or Kruger once made a remark to that effect. That rather than an indictment of stupid people, it would be better to view it as a warning to those who consider themselves the smart ones.
Unfortunately the original article isn't very clearly explained, and it's only on reading the discussion in the comments under it that it becomes clear what it's actually saying.
The point is about signal & noise. Say your random variable X contains a signal component and a noise component, the former deterministic and the latter random. Say you correlate Y-X against X, and further say you use the same sample of X when computing Y-X as when measuring X. In this case your correlation will include the correlation of a single sample of the noise part of X with its own negation, yielding a spurious negative component that is unrelated to the signal but arises purely from the noise. The problem can be avoided by using a separate sample of X when computing Y-X.
The example in the original "DK is autocorrelation" article is an extreme illustration of this. Here, there is no signal at all and X is pure noise. Since the same sample of X is used a strong negative correlation is observed. The key point though is that if you use a separate sample of X that correlation disappears completely. I don't think people are realising that in the example given the random result X will yield another totally random value if sampled again. It's not a random result per person, it's a random result per testing of a person.
This is only one objection to the DK analysis, but it's a significant one AFAICS. It can be expected that any measurement of "skill" will involve a noise component. If you want to correlate two signals both mixed with the same noise sources you need to construct the experiment such that the noise is sampled separately in the two cases you're correlating.
Of course the extent to which this matters depends on the extent to which the measurement is noisy. Less noise should mean less contribution of this spurious autocorrelation to the overall correlation.
To give another ridiculous, extreme illustration: you could throw a die a thousand times and take each result and write it down twice. You could observe that (of course) the first copy of the value predicts the second copy perfectly. If instead you throw the die twice at each step of the experiment and write those separately sampled values down you will see no such relationship.
What you're saying is that we need to verify the statistical reliability of the skill tests DK gave, and to some extent that we need to scrutinize the assumption that there indeed is such a thing as "skill" to be measured in the first place. I hope we can both agree that skill exists. That leaves the test reliability (technical term from statistics, not in the broad sense).
What's simulated by purely random numbers is tests with no reliability whatsoever. Of course if the tests DK gave to subjects don't actually measure anything at all, the DK study is meaningless. If that's what the original article's author is trying to say, they sure do it in a very roundabout way, not mentioning the test reliability at all. I'd be completely fine reading an article examining the reliability of the tests. Otherwise, I again fail to see how the random number analysis has anything to do with the conclusions of DK.
In fact, DK do concern themselves with the test reliability, at least to some extent. That doesn't appear in the graph under scrutiny but appears in the study.
If you assume the tests are reliable, and you also assume that DK are wrong in that people's self-assessment is highly correlated with their performance, and generate random data accordingly, you'll still get no effect even if you sample twice as you propose.
> The key point though is that if you use a separate sample of X that correlation disappears completely
Separate sample of X under the assumption of no dependence at all of the first sample, i.e., assuming there is no such a thing as skill, or assuming completely unreliable tests. So, not interesting assumptions, unless you want to call into question the test reliability, which neither you nor the author are directly doing.
My understanding is that the hypothesis is "Those who are incompetent overestimate themselves, and experts underestimate themselves".
DK says: True
DK is Autocorrelation says: ???
"I cant let go..." says: True?
HN says: also True?
Is there really any debate here? The "DK is Autocorrelation" article seems to be the only odd one out, and it's not clear if it even makes a proposal either way about the DK hypothesis. It talks about the Nuhfer study, but that seems Apples vs Oranges since it buckets by education level. Then it also points out that random noise would also yield the DK effect. But that also does not address the DK hypothesis, and it would indeed be very surprising if people's self evaluation was random!
So should my takeaway here just be that the DK hypothesis is True and that this is all arguing over details?
DK is Autocorrelation says: The DK article is based on a false premise, we got to disregard it
"I cant let go..." says: Actually, given that we assume people are somewhat capable of self-assessment, which is reasonable, "DK is Autocorrelation" is the one based on a false premise, and we should disregard that one instead, and not DK.
The DK hypothesis is "double burden of the incompetent": "Because incompetent people are incompetent, they fail to comprehend their incompetence and therefore overestimate their abilities more than expertes underestimate theirs"
Arguably the hypothesis that matches the data from the DK paper best is: "Everyone thinks they're average regardless of skill level"
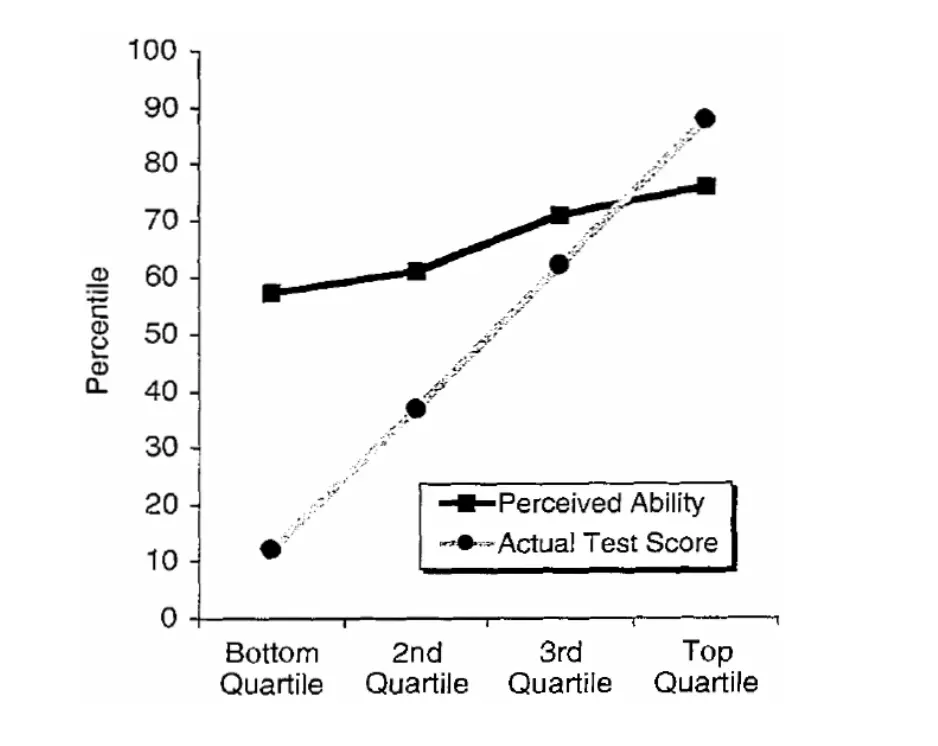
The actual DK result (which is much criticized, but that's a different issue) was actually a pretty much linear relationship between actual relative performance and self-estimated relative performance, crossing over at about the 70th percentile.
(Because there is more space below 70 than above, that also means that the very bottom performers overestimated their relative performance more than top performers underestimated, not because of any “double burden” (overstimation didn't rise faster as one moved below the crossover), but just because there was more space below the crossover point.
> Arguably the hypothesis that matches the data from the DK paper best is: "Everyone thinks they're average regardless of skill level"
If there was a perceptual nudge toward average relative performance, you'd expect a crossover at the median with a slope below 1, the nudge is toward a particular point above average.
Sure, there's in aggregate a slight positive slope to self-assessment when plotted against performance. But all of these have in common that the range of self-assessments is small across the full range of performances and they're all centered somewhere around 60.
> The actual DK result
The "incompetent self-assessment because incompetent" claim is literally everywhere in the paper. It's in the title, the abstract, the introduction and every section thereafter until the end.
No, if you look at the graph[0] everyone thinks they are above average (over 50). The worst think they are a little above average and everyone else thinks they are better and better but increasing by less than the real difference.
At any rate, the issue seems to be with how people imagine everyone performs - they seem to think there are a lot of people who are really bad for a start, and seemingly a bit more people who are really good than there are (at least if we assume the results are accurate).
0. https://andersource.dev/assets/dk-autocorrelation/dk.webp
This is so well understood there’s even a joke about it re: drivers that everyone “gets” even while knowing it doesn’t apply to them.
But to your point, look at the slope in the second chart here, “Histogram of subjective ranks”:
https://gottwurfelt.com/2012/02/28/why-everyone-thinks-theyr...
Compare to DK slope…
I hate it when people are "solely2 using statistics, and other first-principle thinking approaches, to understand well researched and documented topics. And I hate it if people use solely statistics to criticize research without considering the other aspects of it. Does it mean the DK effect can be discarded or not? I don't know, I think some disagreement over the statistical methods is not enough to come to any conclusion.
Attacking the Dunning-Kruger study only on statistical grounds looks like aprime example of the DK effect in itself...
Observation: if you rank via true "skill" and assume for a particular instance the predicted performance and observed performance are independent but both have the true skill as their mean you dont observe the effect. CC of 0.00332755.
If you rank via observed performance and plot observed vs predicted the effect is there. CC of -0.38085757.
This is assuming very simple gaussian noise which is not going to be accurate especially as most of these tasks have normalised scores.
Edit: fixed wrong way around
https://colab.research.google.com/drive/1Vy7JjkywxwEP8nfR6oS...
What your simulation includes and the original article didn't (and I didn't touch at all in my article) is the statistical reliability of the tests they administered. Where you got a CC of -0.38 you used equal reliability (/ unreliability) of the skill tests and self-assessments. You can see that as you increase the test reliability, the CC shrinks and the effect disappears.
I have no idea what's the actual reliability of the DK tests, they do seem to consider that but maybe not thoroughly enough. In my view it's very fair to criticize DK from that angle. But that would require looking at the actual tests and their data.
My point being, that any purely random analysis is based on assumptions that can easily be tweaked to show the same effect, the opposite effect, or no effect at all.
My hypothesis would be that some of the DK effect in the original paper may be down to an effect like this (as suggested in the original article) but that asserting it is completely incorrect because of it is premature. We'd need access to more data to verify that the level of reliability was sufficiently acceptable.
So my suspicion is that the DK effect is not really a symptom of people's inability to accurately self-assess, but they're unwillingness to accurately report that self-assessment.
And I don't think it is unique to self assessment either. It's common knowledge that ratings on a scale out of 10 for pretty much everything are nearly always between 6 and 9.
I don't know how they did the experiment but I bet they'd get different results if the self-assessments were anonymous and accuracy came with a big financial reward.
Anyway that's all irrelevant to the point of the article which I think is correct.
And that's the point the original article was trying to make ("The reason turns out to be embarrassingly simple: the Dunning-Kruger effect has nothing to do with human psychology. It is a statistical artifact — a stunning example of autocorrelation."), though that point does lost a bit as it goes on.
I think this article gives a better summary of how the Dunning-Kruger effect probably isn't a psychological effect: https://www.mcgill.ca/oss/article/critical-thinking/dunning-...
This isn't true either. Statistical dependence does not determine or uniquely identify causal interpretation or system structure. See Judea Pearl's works (e.g. The Book of Why) for more on this.
People lacking the ability to self-assess is interesting psychologically. People can learn from experience in many other contexts. People can judge their relative position versus other people in many contexts. Why would they be so bad at this particular task? There could be a psychological underpinning.
Even if it turns out we have useless noise-emitting fluff in the place that would produce self-awareness of skill, that would be a psychological cause of a psychological effect. Not the ones that Dunning and Kruger believed they were seeing, but still.
Now, if you asked frogs for a self-assessment of skill, I would expect that data would not show any psychological effects.
Is there an existing and relevant phenomenon about people lacking the ability to self-asses, that is true, proven, and not just trivia?
I do believe that people understand all the available information about their skills and performance, and they rate themselves according to it.
E.g. if they are asked about whether they perform good on an IQ test against their classmates they will produce noise (see E.g. the article "I can't let go of.."), and if they have the results of the IQ test, they will be able correctly calculate in which quartile they are.
Is there anything against this view?
It makes sense as a robotically developed null hypothesis, but it doesn't make sense in the real world.
1) an incompetent person is poorer than average at self assessment of their skill
2) as a person's competence increases at a skill, their ability to self-assess improves, until they become 'expert' which is defined by underappreciating their own skill (or overappreciating the skill of others)
3) DK is surprising (interesting) only when some incompetent persons who suffer from DK cannot improve their performance, presumably because their poor self-assessment prevents their learning from experience or from others.
4) Worse yet, some persons suffering from DK cannot improve their performance in numerous skill areas, presumably because their poor self-assessment is caused by a broad cognitive deficit (e.g. political bias), preventing them from improving on multiple fronts (which are probably related in some thematic way).
If DK is selective to include only one or two skill areas, as in case 3, that is not especially surprising, since most of us have skill deficits that we never surmount (e.g. bad at math, bad at drawing, etc). DK becomes surprising only in case 4, when we claim there is a select group of persons who have broad learning deficits, presumably rooted in poor assessment of self AND others — to wit, they cannot recognize the difference between good performance and bad, in themselves or others. Presumably they prefer delusion (possibly rooted in politics or gangsterism) to their acknowledgement of enumerable and measurable characteristics that separate superior from inferior performance, and that reflect hard work leading to the mastery of subtle technique.
If case 4 is what makes DK surprising, then DK certainly is not described well by the label 'autocorrelation' — which seems only to describe the growth process of a caterpillar as it matures into a butterfly.
The surprising things about DK, to me at any rate, is how unvarying it is in application. Under DK people who are poor at something never think wow I really suck at this, or if they do they are such a minuscule part of the population that we can discount them.
I've known lots of people who were not good at particular things and did not rate themselves as competent at it, although truth is they might have claimed competence if asked by someone they didn't want to be honest with.
And this tracks for most skills. How good are you at tying your shoes? Probably average? Just how good can you get? Probably not that much better, all told. It is a clearly defined goal and likely has a limit on the skill you can build.
What about writing your name? Putting on your clothes? Making your bed? All things that are somewhat bound in just how good you can be.
Now, throw in something like "play the piano." Turns out, the expertise bar is much much higher suddenly. But, it you haven't been trying, how would you know?
(My recommendations are: When you really need your laces to hold, the Mega Ian Shoelace Knot - https://www.fieggen.com/shoelace/megaianknot.htm ; and for most shoes and definitely all laced boots (and absolutely for ice skates!), the Over Under Lacing: https://www.fieggen.com/shoelace/overunderlacing.htm .)
In fact, this is pretty much what the Dunning-Kruger graphs look like. The article shows the one for humor which has the bottom quartile participants answer "eh, about average" while the top quarter of participants realize they're better than average, but estimate roughly 75-percentile rather than 87.5-percentile.
The author says as much in this article:
> Why so angry? [...] [Frankly], for the last few years, the world seems to be accelerating the rate at which it’s going crazy, and it feels to me a lot of that is related to people’s distrust in science (and statistics in particular). Something about the way the author conveniently swapped “purely random” with “null hypothesis” (when it’s inappropriate!) and happily went on to call the authors “unskilled and unaware of it”, and about the ease with which people jumped on to the “lies, damned lies, statistics” wagon but were very stubborn about getting off, got to me. Deeply. I couldn’t let this go.
It's true, the previous article (https://economicsfromthetopdown.com/2022/04/08/the-dunning-k...) was pretty harsh on the authors of the original paper:
> In their seminal paper, Dunning and Kruger are the ones broadcasting their (statistical) incompetence by conflating autocorrelation for a psychological effect. In this light, the paper’s title may still be appropriate. It’s just that it was the authors (not the test subjects) who were ‘unskilled and unaware of it’.
But on some level, the original paper sounds just as condescending and dismissive. It presents a scholarly and statistical framework for looking down on "the incompetent" (a phrase used four times in the original paper). In practice, most of the times I see the DK effect cited, it functions as a highbrow and socially acceptable way of calling someone else stupid, in not so many words.
Cards on the table, I've never liked DK discourse for this reason. It's always easy to imagine others as the "Unskilled and Unaware", and for this reason bringing DK into any discussion rarely generates much insight.
I think it's even worse that that: it's also a socially acceptable way of enforcing credentialism and looking down on others for not having a sufficiently elite education.
For example, if someone gave me (or you) a leetcode-style test, and told me I'd be competing against a sample picked from the general population, and ask me how well I did, I'd probably rate myself near the top with high confidence.
Conversely, if my competitors were skilled competitive coders, I'd put myself near the bottom, again with high confidence.
Now, if I had to compete with a different group, say my college classmates, or fellow engineers from a different department, I'd be in trouble, if I scored high, what does that mean? Maybe others scored even higher. Or if I couldn't solve half of the problems, maybe others could solve even less - point is I don't know.
In that case the reasonable approach for me would be to assume I'm in the 50th percentile, then adjust it a bit based on my feelings - which is basically what happened in this scenario, and would produce the exact same graph if everyone behaved like that.
No need to tell tall tales of humble prodigies and boastful incompetents.
I find the use of quartiles suspicious, personally. It's very nearly the ecological fallacy[1].
> I’m not going to start reviewing and comparing signal-to-noise ratios in Dunning-Kruger replications
DK has been under fire for a while now, nearly as long as the paper has existed[2]. At present, I am in the "effect may be real but is not well supported by the original paper" camp. If DK wanted to they could release the original data, or otherwise encourage a replication.
[1]: https://en.wikipedia.org/wiki/Ecological_correlation [2]: https://replicationindex.com/2020/09/13/the-dunning-kruger-e...
1. Average self assessment coincides with true skill, but variance increases with low skill.
2. Average self assessment is biased, and the bias is positive when you are unskilled and negative when you're highly skilled.
These two situations would create indistinguishable DK-graphs. I don't understand how anyone can be sure on either (1) or (2) after seeing one instance of such a graph.
As I see it, the only way out for "DK positivists" is to say that the DK hypothesis is unrelated to the truth values of (1) and (2). Or, that there is other evidence making DK convincing.
Neither seems very plausible!
It's definitely related to ecological fallacy in the sense that both underestimate relative error and inflate effect sizes.
If others can't replicate it entirely on their own without "encouragement". Then it isn't useful at all and the original experiment can be safely ignored as irrelevant to humanity, along with any "prestige" associated with it.
This is not possible, so the self-assessment data will be random because it is a random guess... so it does not correlate to actual performance or anything else for that matter. Hence, DK effect has to be a result of faulty statistical analysis.
I believe we'd have completely different results if the question was framed differently: "how many do you believe you got right?". Then, more confident people, regardless of competence, would answer that they got more right and less confident people, again regardless of competence, would believe that they must have gotten more wrong than they did.
I stopped reading at this point. Someone that is so certain that they say “I simply won’t believe you.” is too self-assured to be worth paying much attention to.
Actually it is even more ironic. You are too self-assured that a multi-page article is not worth paying attention to because of a single sentence in it that irritates you.
> “Never assume dependence” gets so ingrained that people stubbornly hold on to the argument in the face of all the common sense I can conjure. If you still disagree that assuming dependence makes more sense in this case, I guess our worldviews are so different we can’t really have a meaningful discussion.
Hypothesis testing is concerned with minimization of Type I and Type II errors. In the Neyman-Pearson framework this calls for specific choice of the null hypothesis. Of course nothing prevents you to define the sets for H0 and H1 as arbitrarily as you want as long as you can mathematically justify your results.
It seems like the author fundamentally misunderstands the basics of statistics.
It bugs me that DK reached popular consciousness and get misinterpreted and misused more often than not. For one, the paper shows a positive correlation between confidence and skill. The paper is very clearly leading the reader, starting with the title. The biggest problem with the paper is not the methodology nor the statistics, it’s that the waxy prose comes to a conclusion that isn’t directly supported by their own data. People who are unskilled and unaware of it is not the only explanation for what they measured, nor is that even particularly likely, since they didn’t actually test anyone who’s verifiably or even suspected to be incompetent. They tested only Cornell undergrads volunteering for extra credit.
Put differently, if everyone's estimate was exactly the mean, you'd still see a "DK effect".
It’s also an interpretation to focus on unskilled people as the explanation. DK’s data shows the very same effect on highly skilled people. The people in the top quartile were just as bad at self-estimating as the bottom quartile, yet the paper claims only the unskilled people were unaware!
I recommend reading the DK paper. It didn’t test any people of low ability, and it did not evaluate skill in absolute terms. The sample size was tiny. The kids who participated were all earning extra credit in a class (it’s a self-selecting population that might have excluded both A students and F students.) The students were all Ivy League undergrads who might all overestimate their abilities precisely because they’re in a prestigious school and their parents told them they’re great. The paper didn’t test any actual low IQ population. The paper has methodology problems when it comes to non-native English speakers.
It absolutely blows my mind that the paper is held up as evidence for some kind of universal human trait with such miniscule and completely questionable evidence. I have no doubt that some people overestimate their abilities in some situations. Like you, I’m sure, I’ve witnessed that. But as a commentary on all of humanity, I’m becoming convinced that the so-called DK effect does not exist, that they didn’t show what they claim to show. It doesn’t help that many replication attempts have not only failed to replicate, but have ended up showing the opposite effect: that for many kinds of skilled activities, people.
If people wander off through the verbiage of any article, where the chatter isn't supported by data, sure, they'll tend to get speculation.
Imagine in the Dunning-Kruger chart the second plot (perceived ability) was a horizontal line at 70, which is not true but not far off from the real results. Now imagine I told you "did you know that, regardless of their actual score, everyone thought they got a 70?" That's a surprising fact.
There's really no contradiction there; all it takes is for there to be a couple low scores pulling the average down.
The arithmetic mean and the median are both averages, but the upthread comment was about the median and yours about the arithmetic mean.
> There's really no contradiction there; all it takes is for there to be a couple low scores pulling the average down.
Well, no, when what you are estimating is relative performance by score percentiles, and people's self evaluation is biased toward the 70th percentile, that's not what is happening.
I honestly think people take it way too seriously and apply it too generally. Quantifying "good" is hard if you don't know much about the field you're quantifying. Getting deep into a particular field is humbling -- Tetris seems relatively simple, but there are people who could fill a book with things _I_ don't know about it, despite playing at least a few hundred hours of it.
Is there an answer to that humility gained by being an expert in one field being translated to better self-assessment in other fields? I feel myself further appreciating the depth and complexity of fields I "wrote off" as trivial and uninteresting when I was younger as I get deeper into my own field (and see just how much deeper it is too).
I think that often the opposite is true: people who become experts in one domain often assume that they are automatically experts in completely unrelated fields. I suspect that this is the cause of "Nobel disease": https://en.wikipedia.org/wiki/Nobel_disease
"there's nothing more annoying than a physicist encountering a new subject"
What I'm really missing is a plot of the data without the aggregation. I find it very strange that X is broken down into quartiles but Y isn't, and when in quartiles, people estimated their skills relative to each other quite well: the line still goes up, and from bottom to top, would be a perfect X to X corelation
In partial "defense" of the "autocorrelation" article, the author was in fact arguing against their own perceived definition of DK, not what most people consider to be DK. They just didn't realise it.
Which is an all too common thing to begin with. (that particular article pulled the same stunt with the definition of the word 'autocorrelation', after all).
(That's not to criticize OP - when someone makes an argument that sounds convincing, it can be pretty convincing! It's just different than actually being valid.)
I don't have this luxury in my life right now but I admit after reading the "original" post almost a fourth time, I was really hoping someone would take the time to explain why/how the author could be completely wrong (or not).
Thanks.
The issue is not the way our brains generalize, but that you are using just one brain, one life's experience.
Except that what you've plotted there isn't the growth rate, but the absolute growth. Your argument for DK isn't convincing either, they claimed sth much stronger than that we can't assess our own skills.
Daniel: >It’s not a “statistical artifact” - that will be your everyday experience living in such a world.
You can experience statistical effects. I think a lot of controversy comes from how Dunning and Kruger's paper leads people to interpret the data as hubris on the part of low-performers, and the statistical analysis demolishes that interpretation. Not knowing how well you performed is not the same thing psychologically as "overestimating" your performance.
Dunning Krueger is precisely about the surprising result that people are bad at estimating their performance!
If you accept the 'D-K is autocorrelation' argument, you don't get to throw out the existence of the D-K effect: you are saying Dunning + Krueger failed to show that humans have any ability to estimate how skilled they are at all.
That seems like an even more radical position than the D-K thesis.
Isn't DK about estimating your performance relative to the rest of the population? To do that, you need to not only know your own performance but also everyone else's. To me, guessing the performance of others sounds quite difficult.
Of course, there are tests where the bottom quartile find the majority of it easy and have no particular reason to assume that most others found it even easier, and circumstances in which the weak undergrad who can only answer half the questions may reasonably believe that the test is being administered to a general population full of people who won't understand any of the material at all. But in general, it's reasonable to assume that if there's a lot of stuff you don't know, other people will know better.
You are sort of smuggling in the assumption for example that Olympian medalist lifters, when asked how much they can deadlift, will have the same distribution of answers as people who never deadlift (but are aware that totally sedentary men can probably deadlift like 200lbs and totally sedentary women can probably deadlift like 150lbs). If this were true, it would be worth publishing a paper about it.
It's sort of surprising to me to read your comment because TFA is an extended rebuttal of your comment.
> I think a lot of controversy comes from how Dunning and Kruger's paper leads people to interpret the data as hubris on the part of low-performers, and the statistical analysis demolishes that interpretation. Not knowing how well you performed is not the same thing psychologically as "overestimating" your performance.
D-K actually found that low performers were less accurate at assessing their skill than high performers, and the article you refer to obviously did not find this effect in random data, so I'm not sure how it was demolished.
A sentence, written by the author on, commented by me on and read by the HN community on devices, which exist only thanks to 80-90 years of rigorous, statistics based QA in engineering, especially in mechanical/hardware engineering.
Anyhow, after spending years on a team filled with social science PHDs, I would not waste my time on reading papers about statistical analysis done by social scientist.
> We don't [only] need [the formal discipline of mathematics known as] statistics to learn about the world.
Sure, there are things you can only functionally ascertain through statistical analysis. But not everything in the world needs rigorous statistics.
First one means "throw it away". Second one means "add other things too".
And I think you are injecting the words "only", "there are" and "everything" here and there just to change the meaning of the sentences I quoted and I have written...
However, by "random data", the original blog means people and their self-assessments are completely independent! In fact, this is exactly what the DK effect is saying -- people are bad at self-evaluating [2]. (More precisely, poor performers overestimate their ability and high performers underestimate their ability.) In other words, the premise of the original blog post [1] is exactly the conclusion of DK!
Looking at the HN comments cited [3] by the current blog post, it appears that the main point of contention from other commenters was whether the DK effect means uncorrelated self-assessment or inversely correlated self-assessment. The DK data only supports the former, not the latter. I haven't looked at the original paper, but according to Wikipedia [2], the only claim being made appears to be the "uncorrelated" claim. (In fact, it is even weaker, since there is a slight positive correlation between performance and self-assessment.)
So, my conclusion would be that DK holds, but it does depend on exactly what is the exact claim in the original DK paper.
[1] https://economicsfromthetopdown.com/2022/04/08/the-dunning-k...
[2] https://en.wikipedia.org/wiki/Dunning%E2%80%93Kruger_effect
Is it that hard to actually check the original paper before bothering to make such a claim? The original paper explicitly claims to examine "why people tend to hold overly optimistic and miscalibrated views about themselves".
Their claim that "If we have been working with random numbers, how could we possibly have replicated the Dunning-Kruger effect?" is the first blatantly false statement, and then the rest is built upon that so it can be safely disregarded.
It's easy to see this because while the effect is present if everyone evaluates themselves randomly, it's not present if everyone accurately evaluates themselves, and these are both clearly possible states of the world a priori, so it's a testable hypothesis about the real world, contrary to the bizarre claim in the paper.
Also, the knowledge that the authors published that article provides evidence for the Dunning-Kruger effect being stronger than one would otherwise believe.
Like similar analyses here you don't factor in that DK is about bias. Of course you can't see bias when test score=self assessment. That's because "IF everyone perfectly knows their score then there is no bias in their assessment" is a tautology.
Most comments were splitting hairs on what _exactly_ the Dunning-Kruger effect was, plus some general nerd-sniping on how the original article was off base.
IMO it was something that fell flat on its own rather than something that needed a lengthy refutation, but I can understand that sometimes these things get under your skin.
Edit-see below I meant opposite not corollary.
Now with D-K the proposed problem is statistical autocorrelation, not systematic bias, due to lack of independence, as here:
> "Subtracting y – x seems fine, until we realize that we’re supposed to interpret this difference as a function of the horizontal axis. But the horizontal axis plots test score x. So we are (implicitly) asked to compare y – x to x"
Regardless, it's fairly obvious that D-K enthusiasts are of the opinion that a small group of expert technocrats should be trusted with all the important decisions, as the bulk of humanity doesn't know what's good for it. This is a fairly paternalistic and condescending notion (rather on full display during the Covid pandemic as well). Backing up this opinion with 'scientific studies' is the name of the game, right?
It does vaguely remind me of the whole Bell Curve controversy of years past... in that case, systematic bias was more of an issue:
> "The last time I checked, both the Protestants and the Catholics in Northern Ireland were white. And yet the Catholics, with their legacy of discrimination, grade out about 15 points lower on I.Q. tests. There are many similar examples."
https://www.nytimes.com/1994/10/26/opinion/in-america-throwi...
I am reminded of something my very accomplished PI (in the field of earth system science) confided privately to me once... "Purely statistical arguments," she said, "are mostly bullshit..."
It seems like you're roughly the only person who thinks this.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}