I spent a lot of time in the early 2000s coming up with nasty obfuscation techniques to protect certain IP that inherently needed to be run client-side in casino games. Up to and including inserting bytecode that was custom crafted to intentionally crash off-the-shelf decompilers that had to run the code to disassemble it (and forcing them to phone home in the process where possible!)
My view on obfuscation is that since it's never a valid security practice, it's only admissible for hiding machinery from the general public. For instance, if you have IP you want to protect from average script kiddies. Any serious IP can be replicated by someone with deep pockets anyway. Most other uses of code obfuscation are nefarious, and obfuscated code should always be assumed to be malicious until proven otherwise. I'm not a reputable large company, but no reputable large company should be going to these lengths to hide their process from the user, because doing so serves no valid security purpose.
For example, in our application we have some optionally downloadable content that includes some code for an interpreted language. That code lives on disk in an obfuscated form because we are not yet ready to make the API public (it's on our "someday" roadmap), we don't want to clean up the code for public viewing, and above all because there are different licensing requirements around each content pack.
We looked at various "real" security options and they all have holes, and they all add a ton of complexity. We then also looked at the likely intersection between "people who would pay for this" and "people who could crack this", and there's not much there. In the end, obfuscation is cheap (especially in terms of implementation and maintenance) and steers our real customers away violating the license, and we don't waste resources on dishonest people.
If I'm being charitable, the obfuscation in the article has an out of whack cost/benefit ratio. If I'm being cynical, the obfuscation they are doing strays well into the realm of nefarious. :)
> it's only admissible for hiding machinery from the general public.
I had originally read this to imply that somehow it's OK for a casino to hide its machinery from the general public, but it's not OK for TikTok to hide its machinery from the general public, but maybe "machinery" here is intended much more narrowly, and OP thinks it applies neither to casinos nor TikTok.
I felt it was important to make it as hard as possible for someone to reverse engineer the unique mechanisms. Ultimately, it was probably a waste of time. This is why I think in most cases the uses of obfuscation are at best limited, but they can put a costly stumbling block for competitors if you want to encourage them to license your software rather than copy it. Where I think they tilt toward the nefarious is when they're designed to extract hidden data from end users. As a distinction, what went over the wire between the client game modules and the casino back-end were completely human-readable game states in all cases (besides the user's unique ID and session hash, which were named as such). There were no bullets of obfuscated fingerprints flying around. Any user was free to read what came and went from the API, and even to mess with it by adjusting parameters if they wanted to see what the server would accept or reject.
Random numbers are never generated in the client. Ours were generated on dedicated server separate from anything else - in a different country, for legal reasons - whose sole purpose was to generate random numbers on demand.
Number generation is extremely important and it's also regulated. You don't put such a thing in the client obfuscated or not.
Why not? It's just another tool in the security game.
I want to be with you on thinking that all obfuscation is malicious, I know that individuals have every right to obfuscation and privacy as a matter of the 1st and 4th amendments in the US, but I'm not sure I can always say that obfuscation by a corporation is evil, without a more compelling argument. I'm as anti-establishment as they come, too.
This shows how browser developers race to provide new features ignoring privacy impact.
I don't understand why features that allow fingerprinting (reading back canvas pixels or GPU buffers) are not hidden behind a permission.
Now, it is true that a lot of older web APIs do expose too much fingerprinting surface. But the design sensibilities having changed a lot over time, it's just not the case that you can make statements about what browser developers do now based on what designs from a decade or two ago look like. These days privacy is a top issue when it comes to any new browser APIs.
But let's take your question at face value: why aren't thesespecific things behind a permission dialog? Because the permissions would be totally unactionable to a normal user. "This page wants to send you notifications" or "this page wants to use the microphone" is understandable. "This page wants to read pixels from a canvas" isn't. If you go the permission route, the options are to either a) teach users that they need to click through nonsensical permission dialogs, with all the obvious downsides; b) make the notifications so scare or the permissions so inaccessible that the features might as well not exist. And the latter would be bad! Because the legit use cases for e.g. reading from a canvas do exist; they're just pretty rare.
The Privacy Sandbox approach to this is to track and limit how much entropy a site is extracting via these kinds of side channels. So if you legit need to read canvas pixels, you'll have to give up on other features that could leak fingerprinting data. (I personally don't really believe in that approach will work, but it is at least principled. What I'd like to see instead is limiting the use of these APIs to situations where the site has a stable identifier for the user anyway. But that requires getting away from implementing auth with cookies as opaque blobs of data with unknown semantics, and moving to some kind of proper session support where the browsers understands the semantics of signed-in session, and it's made clear to users when they're signing in somewhere and where they're signed in right now. And then you can make a lot better tradeoffs with limiting the fingerprinting surface in the non-signed in cases.)
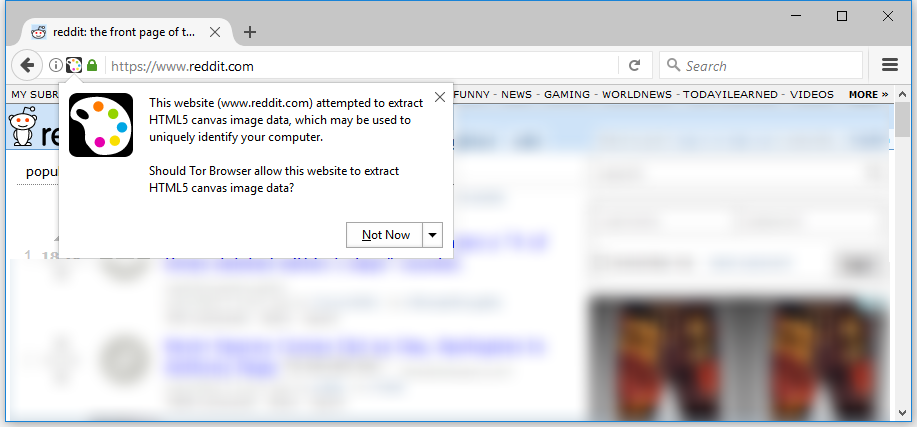
Yes, it is. Tor Browser already does this: https://www.bleepstatic.com/content/posts/2017/10/30/CanvasF...
That specific wording may be a touch too verbose for the average end user, but it's not impossible nor is it strange. Just include a note about how this is 99% likely a fingerprinting measure; option b) isn't so bad in this case. Of course, due to the nature of how fingerprinting works, the absolute breadth of features that would be gated behind something like this would be offputting.
I am also wary of what you suggested with gating this kind of fingerprinting to when the website has positively identified the user anyway; in a way, this seems to me even more valuable than fingerprint data without an associated "strong" identity.
WebRTC is instantiated most often by ad networks and anti-fraud services.
Same thing with Chrome's fundamentally insecure AudioContext tracking scheme (yes, it's a tracking scheme), which is used by trackers 99% of the time. It provides audio latency information which is highly unique (why?).
Given Chrome's stated mission of secure APIs and their actions of implementing leaky APIs with zeal, I have reason enough to question their motives.
After all, AudioContext is abused heavily on Google's ad networks. Google knows this.
As someone who has worked with WebAudio extensively, and have opened and read many issues in the bug tracker and read many of the proposals... this is just not as nefarious as you are making it seem. I don't disagree that this _can_ be abused by ad tracking networks but I do disagree with the premise that it was somehow an oversight of the spec or implementation which led to this (or even worse, intentional). Providing consistent audio behavior across a wide variety of platforms (Linux, OSX, Windows, Android) along with multiple versions of all those platforms and the myriad hardware in the actual devices is actually just pretty hard. The boring answer here is that to provide low latency audio to support things like games, a lot of decisions have to made about what buffer sizes are appropriate for the underlying hardware and this is what ultimately exposes some information about audio latency on the system. Some of those decisions are limited by the audio APIs of the OS. Some are limited by the capabilities of the hardware. Some are workaround for obscure bugs in either layer. The point is that, as with most software, compromises are made to support an API that people actually need or want to use to make stuff. I also don't think audio latency information is really "highly unique". There are only a handful of buffer sizes which are reasonable based on the desired sample rate and are mostly limited by the OS, meaning at best you can probably identify a persons OS via the AudioContext. Furthermore, I have seen API "improvements" and requests rejected outright due to possibly exposing fingerprinting information. Things that would be really useful to applications which are building audio-centric software won't be implemented because the team takes this issue seriously.
But I suspect by the other two metrics it's correct to say most uses are to fingerprint.
- Your timezone is reported to be UTC
- Not all fonts installed on your computer are available to webpages
- The browser window prefers to be set to a specific size
- Your browser reports a specific, common version number and operating system
- Your keyboard layout and language is disguised
- Your webcam and microphone capabilities are disguised
- The Media Statistics Web API reports misleading information
- Any Site-Specific Zoom settings are not applied
- The WebSpeech, Gamepad, Sensors, and Performance Web APIs are disabled
https://support.mozilla.org/en-US/kb/firefox-protection-agai...
I don't think Chrome accidentally exposed data that Google wanted.
The main reason is that it's really hard to avoid fingerprinting (while providing rich features like WebGL and WebRTC anyway).
A secondary reason is that web browsers started off from a position of leaking fingerprint data all over the place so there's not much incentive to care about it for new features.
You might be interested in this effort to reduce fingerprinting: https://developer.chrome.com/en/docs/privacy-sandbox/privacy...
(The real conspiracy is that Google added logins to Chrome specifically so that they don't have to rely on fingerprinting. They have a huge incentive to stop fingerprinting because it leaves them as the only entity that can track users.)
that's the profile icon you see on your google-chrome UI.
but only fools use that feature.
The more benign explanation would be to allow developers to work around device-specific or browser-specific bugs.
(I'm aware Apple changes the GPU Model to "Apple GPU", however they do expose a ton of other properties that make it possible to fingerprint a device.)
[1] fingrprintr.pages.dev
I wonder to what degree we can enable hardware performance without leaking user data.
I think it showed how many years ago browser vendors were naive with understanding how this tech could be misused.
These days I think browser vendors are very much aware of it and will frequently block features or proposals that they feel compromise on privacy and/or could be used as a tracking vector, especially Firefox and Safari. Sort this list https://mozilla.github.io/standards-positions/ by Mozilla Position to see the reason they reject/refuse to implement standards and proposals.
If you change or alter some browser APIs in order to make your browser less unique, some payment processors webs may stop working. And webs proxied through CloudFlare will constantly display "Checking if the site connection is secure" page, sometimes in an infinite loop where even solving their captchas won't help.
Intent is irrelevant, the APIs are fundamentally insecure. Google directly benefits from this financially.
In most parts of the world, if a person is in a public space, anyone can take a photo of that person, including shop owners. This photo could be considered as a type of "fingerprint" for that person. The only important difference is that in some countries, you are not allowed make money off of such photos.
The Internet is a lot like a big public space, and possibly worse - while you are using certain services (web pages or apps), it might be argued that you are actually "on premises" for that service provider.
The best we can do now is more and more education about what can go wrong with such data collection.
1.0.0.200: https://hastebin.com/tudivadufa.apache Unknown version: https://hastebin.com/jasuxineti.js
Some of these might have some console.logs (or curse words), but as a whole should be representative
I had a secondary use case of allowing users to sign-in in order to import the (verified/creator) users they follow, but quickly realized Apple wouldn't allow that data to be used (after the whole OG app ordeal), so I never had a real reason to follow up and crack it again.
[1]: https://github.com/javascript-obfuscator/javascript-obfuscat...
[2]: https://github.com/javascript-obfuscator/javascript-obfuscat...
rusty-jsyc is the main open source implementation I've found, though it hasn't been touched in a few years: https://jwillbold.com/posts/obfuscation/2019-06-16-the-secre... (GitHub: https://github.com/jwillbold/rusty-jsyc)
I think there are other implementations, but they're proprietary so I didn't look into them very much. There are lots of posts out there about reversing virtualization obfuscation, but not many about implementing it. Seems like most people who put the effort into implementing it tend to prefer selling it commercially (which I suppose makes sense).
Renaming variables or encoding them is fairly trivial to reverse.
It also shows how Tiktok may be in violation of several US/EU privacy laws. I really wonder now who this data is shared with. Perhaps someone should bring this article to the FTC’s attention for further review.
https://news.ycombinator.com/item?id=34112874 (TikTok banned on government devices)
https://news.ycombinator.com/item?id=34121201 (TikTok admits to spying on U.S. users)
> If that is something you are interested in, keep an eye out for the second part of this series :)
Your site is missing an RSS/Atom feed, so I can't do that. ::sad face::
https://www.nullpt.rs/feed.atom https://www.nullpt.rs/feed.rss https://www.nullpt.rs/feed.json
It sounds like the forthcoming part 2 article will go into more depth.
a very, very specialized "regex" based JS evaluator that presumably did just enough to make the YT one run: https://github.com/ytdl-org/youtube-dl/blob/2021.12.17/youtu...
and its callsite: https://github.com/ytdl-org/youtube-dl/blob/2021.12.17/youtu...
So the short version is that I would not classify that as a VM, and I don't even believe it's obfuscated. Perhaps there are other extractors that do what you're describing, I didn't go looking
But that explains the obvious subdomain vm.tiktok.com
I have often wondered what the legal area is for sharing a Ghidra database that merely labels existing code, but I haven't looked into how much of the original binary gets packaged up with such a database
More importantly, if you're talking to a browser, the browser's own cache is in play. It's not an edge cache, per se, but it's just as important as one, and acts very similar to one.
Those who care and have to use TikTok can probably add their own virtualization layer (and tolerate the hit in cost/performance).
Kind of. But it was possible at one point, maybe still is, to rebind `undefined` to some other value, causing trouble. `void` is an operator, a language keyword; it’s guaranteed to give you the true undefined value. (In other words, the value whose type is `undefined`.)
If you’re coding against an environment as adversarial as these people clearly believe they are, you’d go with `void` as well.
This decompiled object class also spy on the grid network, that's quite interesting and very clever
I never knew we could also lobby governments to push for some office and cloud software full of spyware, even France had to ban them! [1]
This TikTok app is very dangerous!
Of course /s
What is the reason why China blocks all foreign social media apps within its own borders?
{kind=link}