I have a collection of novel probability and statistics problems at the masters and PhD level with varying degrees of feasibility. My test suite involves running these problems through first (often with about 2-6 papers for context) and then requesting a rigorous proof as followup. Since the problems are pretty tough, there is no quantitative measure of performance here, I'm just judging based on how useful the output is toward outlining a solution that would hopefully become publishable.
Just prior to this model, Gemini led the pack, with GPT-5 as a close second. No other model came anywhere near these two (no, not even Claude). Gemini would sometimes have incredible insight for some of the harder problems (insightful guesses on relevant procedures are often most useful in research), but both of them tend to struggle with outlining a concrete proof in a single followup prompt. This DeepSeek V4 Pro with max thinking does remarkably well here. I'm not seeing the same level of insights in the first response as Gemini (closer to GPT-5), but it often gets much better in the followup, and the proofs can be _very_ impressive; nearly complete in several cases.
Given that both Gemini and DeepSeek also seem to lead on token performance, I'm guessing that might play a role in their capacity for these types of problems. It's probably more a matter of just how far they can get in a sensible computational budget.
Despite what the benchmarks seem to show, this feels like a huge step up for open-weight models. Bravo to the DeepSeek team!
https://huggingface.co/deepseek-ai/DeepSeek-Math-V2 https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
Same with GPT-5: Latest 5.5, prior 5.4, or actually the original 5 (.0)?
You can't talk about model performance without specifying the exact model.
Summary: Opus 4.6 forms the baseline all three are trying to beat. DeepSeek V4-Pro roughly matches it across the board, Kimi K2.6 edges it on agentic/coding benchmarks, and Opus 4.7 surpasses it on nearly everything except web search.
DeepSeek V4-Pro Max shines in competitive coding benchmarks. However, it trails both Opus models on software engineering. Kimi K2.6 is remarkably competitive as an open-weight model. Its main weakness is in pure reasoning (GPQA, HMMT) where it trails Opus.
Speculation: The DeepSeek team wanted to come out with a model that surpassed proprietary ones. However, OpenAI dropped 5.4 and 5.5 and Anthropic released Opus 4.6 and 4.7. So they chose to just release V4 and iterate on it.
Basis for speculation? (i) The original reported timeline for the model was February. (ii) Their Hugging Face model card starts with "We present a preview version of DeepSeek-V4 series". (iii) V4 isn't multimodal yet (unlike the others) and their technical report states "We are also working on incorporating multimodal capabilities to our models."
Have them do multiplication or other complicated arithmetic. You say that isn't difficult. Then why do they burn 200k tokens in 20 minutes without converging? I did a deep exploration to help myself understand here [0].
https://api-docs.deepseek.com/guides/thinking_mode
No BS, just a concise description of exactly what I need to write my own agent.
Western Models are optimizing to be used as an interchangeable product. Chinese models are being optimizing to be built upon.
Example: the second sentence on the first page says “softwares” but “software” is a mass noun that cannot be pluralized.
Example: the third page about tokens has some zipped code to “calculate the token usage for your intput/output” and obviously “intput” should be “input” but misspelled.
As a company that produces LLMs, they could have even used their own LLM to edit their documentation to fix grammar issues, and yet they did not.
Maybe I’m just extra sensitive to grammar and spelling issues but this kind of lack of attention to detail is a huge subconscious turnoff. I had to fight my urge to close the tab.
Pretty cool, I think they're the first to guarantee determinism with the fixed seed or at the temperature 0. Google came close but never guaranteed it AFAIK. DeepSeek show their roots - it may not strictly be a SotA model, but there's a ton of low-level optimizations nobody else pays attention to.
Early takeaways: from this release, DeepSeek V4 Flash is the model to pay attention to here. It's cheap, effective, and REALLY fast.
The Pro model is slow, not much better in coding reasoning so far when it works, and honestly too unreliable and rate limited to be of much use, currently. Hopefully that improves as new providers host the model. Flash is working fine, and is currently performing competitively with recent releases, but only on agentic workflows. Check back in 24 hours for full combined scoring with tool use and long context for both models.
Many of the frontier Chinese AI labs have released near-frontier models that are just a little bit behind Opus 4.6 in terms of speed, tool use ability, or long context handling. Open weights are winning the AI race, led by China. Crazy couple weeks of releases.
Mimo V2.5 Pro by Xiaomi (not open weights) is actually the best performer of the latest string of Chinese releases in our combined, comprehensive benchmarks, despite getting less attention. Kimi K2.6 is the most interesting open weights release, still. DeepSeek is not the leader in the space anymore.
An interesting pattern with the latest string of Chinese releases is the much better agentic boost (models are not as smart out of the box, but their ability to iterate in a loop with tools makes up most of the difference). Deepseek V4 Flash exemplifying this -- not a smart model on the first try, but it makes up for it over the course of a session.
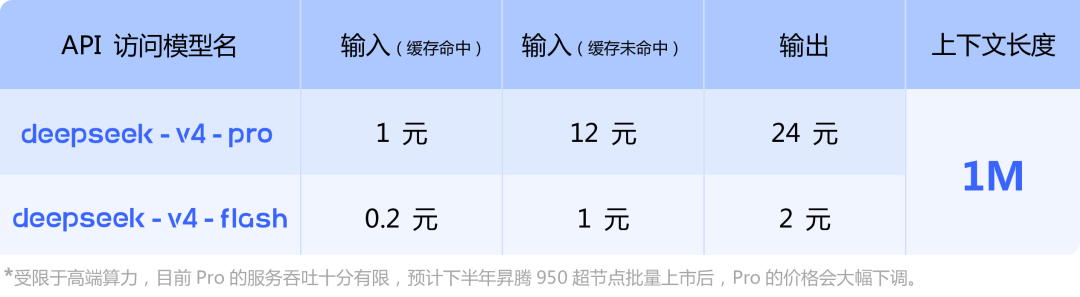
"Limited by the capacity of high-end computational resources, the current throughput of the Pro model remains constrained. We expect its pricing to decrease significantly once the Ascend 950 has been deployed into production."
https://api-docs.deepseek.com/zh-cn/news/news260424#api-%E8%...
I’d like somebody to explain to me how the endless comments of "bleeding edge labs are subsidizing the inference at an insane rate" make sense in light of a humongous model like v4 pro being $4 per 1M. I’d bet even the subscriptions are profitable, much less the API prices.
edit: $1.74/M input $3.48/M output on OpenRouter
We therefore cannot just look at inference costs directly, training is part of the pitch. Without the promises of continuous improvement and chasing the elusive AGI, money for investments for inference evaporates.
In China you need to appease state goals. In the US you need to appease investor goals.
China will keep funding them regardless of their income, because the goal is (ostensibly) a state AGI/ASI. In the US, the goal is an ROI which may or may not come with AGI/ASI.
They are different economies with different goals. We can look at past Chinese national projects and see that they are fine with burning $50 to get [social goal] that's worth $5.
But seriously, it just stems from the fact some people want AI to go away. If you set your conclusion first, you can very easily derive any premise. AI must go away -> AI must be a bad business -> AI must be losing money.
At some point (from the very beginning till ~2025Q4) Claude Code's usage limit was so generous that you can get roughly $10~20 (API-price-equivalent) worth of usage out of a $20/mo Pro plan each day (2 * 5h window) - and for good reason, because LLM agentic coding is extremely token-heavy, people simply wouldn't return to Claude Code for the second time if provided usage wasn't generous or every prompt costs you $1. And then Codex started trying to poach Claude Code users by offering even greater limits and constantly resetting everyone's limit in recent months. The API price would have to be 30x operating cost to make this not a subsidy. That would be an extraordinary claim.
One answer - Chinese Communist Party. They are being subsidized by the state.
Edit: it seems "open source" was edited out of the parent comment.
Also, note that there's zero CUDA dependency. It runs entirely on Huawei chips. In other words, Chinese ecosystem has delivered a complete AI stack. Like it or not, that's a big news. But what's there not to like when monopolies break down?
That is a huge claim to make with no evidence.
I researched what you said, and I have found no statement to that effect in their paper[0], on huggingface[1], twitter[2], WeChat[3], or in their news release[4].
They only mention as a footnote in only the Chinese version of their news release that they plan to reduce inference costs with the Ascend 950 supernode when it releases[5]. The only mention of Huawei in their paper is that they validated a technique to lower interconnect bandwidth on Ascend NPUs and Nvidia GPUs[6].
[0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...
[1] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
[2] https://xcancel.com/deepseek_ai/status/2047516922263285776
[3] https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg
[4] https://api-docs.deepseek.com/news/news260424
[5] https://api-docs.deepseek.com/zh-cn/img/v4-price.png
[6] Page 16
China is not perfect but a bit of competition is healthy and needed
Yes, even compared to this low price point.
As before, the headline news with DeepSeek isn't in the benchmarks, but that they're competitive there while being gut churningly cheap for the Western AI industry.
The report only talks about validating the "fine-grained EP scheme" on Huawei hardware.
Really nice to see the Chinese are competing this strongly with the rest of the world. Competition is always nice for the end-consumer.
So does this mean I can run this on AMD? And on a consumer 9000 series card?
This version of AI is mostly taking a public paper from 2017, investing in GPUs, and feeding it as much data as possible. So with a few computer scientists, no respect for intellectual property, and tons of money to burn, you have all the ingredients to create this technology.
Sam Altman and friends did it, as did the Chinese. The difference is that the Americans have been hyping it up to the extreme with all these dramatic scenarios about what would happen if someone else got its hands on it.
The Chinese made it public, among other things to show how fragile this is as a business and as a large part of the US stock market
Where did you read this? From what I read in the paper it appears to explicitly state that they used NVIDIA GPU's and their MegaMOE code, which is written in CUDA.
And in any case what does open source actually mean for an llm? It's not like you can look inside it to see what it's doing.
I asked DS itself and it denied this. It says: 'Nvidia chips are absolutely used for DeepSeek V4. The reality is a pragmatic "both-and" strategy, not an "either-or."'
And based on the DS V4 technical report (https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...), it is mentioned that:
We validated the fine-grained EP scheme on both NVIDIA GPUs and HUAWEI Ascend NPUs platforms. Compared against strong non-fused baselines, it achieves 1.50 ~ 1.73× speedup for general inference workloads, and up to 1.96× for latency-sensitive scenarios such as RL rollouts and high-speed agent serving.
It mentions that Nvidia is still used. It doesn't even mention that Huawei chips are used in production — only in testing and validation, yes.
New model comes out, has some nice benchmarks, but the subjective experience of actually using it stays the same. Nothing's really blown my mind since.
Feels like the field has stagnated to a point where only the enthusiasts care.
For reference, the huawei Ascend 950 that this thing runs on is supposed to be roughly comparable to nVidia's H100 from 2022. In other words, things are hotting up in the GPU war!
DeepSeek-V4-Flash: https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
DeepSeek-V4-Pro: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
Back in Nov 2025, Opus 4.5 (80.9%) was the first proprietary model to do so.
So it os hard to tell how much of a model gain is due to skill, and how much - overfitting.
And we got new base models, wonderful, truly wonderful
My country’s per capita income is $2500 a year. We can’t pay perpetual rent to OAI/Anthropic
And you think the US tech giants don't have any ulterior motives?!
I just want to remind you that this is happening at the same time as Anthropic A/B tests removal of Code from Pro Plan, and as OpenAI releases gpt-5.5 2x more expensive than gpt-5.4...
That’s a big if. It’s my experience that models that perform very well on benchmarks do not necessarily perform well in real life.
I’ve mostly started ignoring the benchmarks and run my own evals.
input: $0.14/$0.28 (whereas gemini $0.5/$3)
Does anyone know why output prices have such a big gap?
For OSS model, I have z.ai yearly subscription during the promo. But it's a lot more expensive now. The model is good imo, and just need to find the right providers. There are a lot of alternatives now. Like I saw some good reviews regarding ollama cloud.
But more broadly: openrouter solves the problem of making a broad range of models available with a single payment endpoint, so you can just switch around as much as you like.
If you're trying to make a buck while unemployed, sure get a subscription. Otherwise learn how to work again without AI, just focus on the interesting stuff.
Another way to keep the ability to try out new models is to buy a reseller subscription like Cursor’s.
Model was released and it's amazing. Frontier level (better than Opus 4.6) at a fraction of the cost.
As a non-Opus user, I'll continue to use the cheapest fastest models that get my job done, which (for me anyway) is still MiniMax M2.5. I occasionally try a newer, more expensive model, and I get the same results. I have a feeling we might all be getting swindled by the whole AI industry with benchmarks that just make it look like everything's improving.
Claude4.6 was almost 10pp better at at answering questions from long contexts ("corpuses" in CorpusQA and "multiround conversations" in MRCR), while DSv4 was a staggering 14pp better at one math challenge (IMOAnswerBench) and 12pp better at basic Q&A (SimpleQA-Verified).
> In our internal evaluation, DeepSeek-V4-Pro-Max outperforms Claude Sonnet 4.5 and approaches the level of Opus 4.5.
If its coding abilities are better than Claude Code with Opus 4.6 then I will definitely be switching to this model.
There we go again :) It seems we have a release each day claiming that. What's weird is that even deepseek doesn't claim it's better than opus w/ thinking. No idea why you'd say that but anyway.
Dsv3 was a good model. Not benchmaxxed at all, it was pretty stable where it was. Did well on tasks that were ood for benchmarks, even if it was behind SotA.
This seems to be similar. Behind SotA, but not by much, and at a much lower price. The big one is being served (by ds themselves now, more providers will come and we'll see the median price) at 1.74$ in / 3.48$ out / 0.14$ cache. Really cheap for what it offers.
The small one is at 0.14$ in / 0.28$ out / 0.028$ cache, which is pretty much "too cheap to matter". This will be what people can run realistically "at home", and should be a contender for things like haiku/gemini-flash, if it can deliver at those levels.
Was expecting that the release would be this month [1], since everyone forgot about it and not reading the papers they were releasing and 7 days later here we have it.
One of the key points of this model to look at is the optimization that DeepSeek made with the residual design of the neural network architecture of the LLM, which is manifold-constrained hyper-connections (mHC) which is from this paper [2], which makes this possible to efficiently train it, especially with its hybrid attention mechanism designed for this.
There was not that much discussion around it some months ago here [3] about it but again this is a recommended read of the paper.
I wouldn't trust the benchmarks directly, but would wait for others to try it for themselves to see if it matches the performance of frontier models.
Either way, this is why Anthropic wants to ban open weight models and I cannot wait for the quantized versions to release momentarily.
[0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...
[1] https://news.ycombinator.com/item?id=47793880
Do you have a source?
The US-China contest aside - it is in the application layer llms will show their value. There the field, with llm commoditization and no clear monopolies, is wide open.
There was a point in time where it looked like llms would the domain of a single well guarded monopoly - that would have been a very dark world. Luckily we are not there now and there is plenty of grounds for optimism.
I feel uneasy over China dominance as much as the US.
I trust US more still as Europe has a post WW2 relationship. I notice many comments being pro China but they seem to be from the third world (one mentioned a very low salary) I feel the opening of the internet was a mistake.
China is a totilitarian dictatorship. This is a fact.
Look into Mistral AI too :)
For context, I am Swedish.
Yes this is a new account, please focus on the content.
They sanctioned the hell out of Huawei and now Huawei is bigger than ever
America is just not able to digest the idea that another country can be as good, if not better, at innovation
1. There will be no moat where one company "owns" AI. China will see to that. It's simply too much in their national interest for that not to happen;
2. This is incredibly bad news for OpenAI who have raised so much money with so (comparabley( little revenue that the only way they can get a return on that is to "win" and be that company that "owns" AI; and
3. China's chipmaking will catch up with Taiwan within the next decade (with commercial EUV at scale within 5 years). I liken this to American hubris over the development of the atomic bomb where in 1945 many American leaders and military thought the USSR would either never get the atomic bomb or it would take 20+ years. It took 4. And they USSR's first hydrogen bomb was detonated a year after the US's.
Whereas the USSR did this with espionage. times have changed. Now all China has to do is throw a few million dollars at hiring the right people froM ASML and elsewhere. China has the track record of delivering on long term projects. Closing the lithography gap will be no different.
Deepseek is a mid model. not SOTA.
If/when they overtake the US, all things aside, they deserve it. There is no world where the US overtakes China but there’s a world where China overtakes the US. Best outcome for the US atm is parity.
Just remarkable the things they’ve accomplished in the time they’ve accomplished them.
It’s a burned ccp money at this point . They will not be able to serve it until H2 2026 . Even at this point if you look at opus 4.7 and gpt 5.5 this model is just mediocre.
By the time they can serve it nobody will care at all.
I’ve talked to the folks over at Unitree multiple times and they say “yeah we’ll be hiring overseas soon” and then they never do and they only have five openings in China
For me as a consumer, competition is good - that means companies have less leverage over me, which is beneficial even if I decided to never use a Chinese model ever.
its naive to think they would have stayed on a 'western' stack.
Most of the time 'losing' isn't making a bad choice its being put in a situation where you have no good choices.
If I considered myself a 10X programmer, now I am 100X. Love DeepSeek.
For context, for an agent we're working on, we're using 5-mini, which is $2/1m tokens. This is $0.30/1m tokens. And it's Opus 4.6 level - this can't be real.
I am uncomfortable about sending user data which may contain PII to their servers in China so I won't be using this as appealing as it sounds. I need this to come to a US-hosted environment at an equivalent price.
Hosting this on my own + renting GPUs is much more expensive than DeepSeek's quoted price, so not an option.
As a European I feel deeply uncomfortable about sending data to US companies where I know for sure that the government has access to it.
I also feel uncomfortable sending it to China.
If you'd asked me ten years ago which one made me more uncomfortable. China.
But now I'm not so sure, in fact I'm starting to lean towards the US as being the major risk.
It's doesn't seem all that out there compared to the other Chinese model price/performance? Kimi2.6 is cheaper even than this, and is pretty close in performance
This is a pretty interesting thing they've built in my opinion, and not something I'd expect to be buried in the model paper like this. Does anyone have any details about it? Google doesn't seem to find anything of note, and I'd love to dive a bit deeper into DSec.
> We present a preview version of DeepSeek-V4 series, including two strong Mixture-of-Experts (MoE) language models — DeepSeek-V4-Pro with 1.6T parameters (49B activated) and DeepSeek-V4-Flash with 284B parameters (13B activated) — both supporting a context length of one million tokens. DeepSeek-V4 series incorporate several key upgrades in architecture and optimization: (1) a hybrid attention architecture that combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to improve long-context efficiency; (2) Manifold-Constrained Hyper-Connections (mHC) that enhance conventional residual connections; (3) and the Muon optimizer for faster convergence and greater training stability. We pre-train both models on more than 32T diverse and high-quality tokens, followed by a comprehensive post-training pipeline that unlocks and further enhances their capabilities. DeepSeek-V4-Pro-Max, the maximum reasoning effort mode of DeepSeek-V4-Pro, redefines the state-of-the-art for open models, outperforming its predecessors in core tasks. Meanwhile, DeepSeek-V4 series are highly efficient in long-context scenarios. In the one-million-token context setting, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2. This enables us to routinely support one-million-token contexts, thereby making long-horizon tasks and further test-time scaling more feasible. The model checkpoints are available at https://huggingface.co/collections/deepseek-ai/deepseek-v4.
1: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...
https://simonwillison.net/2026/Apr/24/deepseek-v4/
Both generated using OpenRouter.
For comparison, here's what I got from DeepSeek 3.2 back in December: https://simonwillison.net/2025/Dec/1/deepseek-v32/
And DeepSeek 3.1 in August: https://simonwillison.net/2025/Aug/22/deepseek-31/
And DeepSeek v3-0324 in March last year: https://simonwillison.net/2025/Mar/24/deepseek/
As in have the model consider its generated SVG, and gradually refine it, using its knowledge of the relative positions and proportions of the shapes generated, and have it spin for a while, and hopefully the end result will be better than just oneshotting it.
Or maybe going even one step further - most modern models have tool use and image recognition capabilities - what if you have it generate an SVG (or parts/layers of it, as per the model's discretion) and feed it back to itself via image recognition, and then improve on the result.
I think it'd be interesting to see, as for a lot of models, their oneshot capability in coding is not necessarily corellated with their in-harness ability, the latter which really matters.
Let me tell you how much the Pro one sucks... It looks like failed Pedersen[1]. The rear wheel intersects with the bottom bracket, so it wouldn't even roll. Or rather, this bike couldn't exist.
The flash one looks surprisingly correct with some wild fork offset and the slackest of seat tubes. It's got some lowrider[2] aspirations with the small wheels, but with longer, Rivendellish[3], chainstays. The seat post has different angle than the seat tube, so good luck lowering that.
[1] https://en.wikipedia.org/wiki/Pedersen_bicycle
1) LLM is not AGI. Because surely if AGI it would imply that pro would do better than flash?
2) and because of the above, Pelican example is most likely already being benchmaxxed.
How much does the drawing change if you ask it again?
With DS tech though the worry is generally more capacity. Haven't seen issues with v4 but in the past their combination of quality and pricing means they get overloaded.
In my tests too[0], it doesn't reach top 10. One issue, which they also mentioned in their post, is that they can't really serve well the model at the moment, so V4-Pro is heavily rate-limited and gives a lot of timeout errors when I try to test it. This shouldn't be an issue though, considering the model is open-source, but it makes it hard to accurately test at the moment.
[0]: https://aibenchy.com/compare/deepseek-deepseek-v4-flash-high...
I would say I wouldn't notice this wasn't Opus 4.6. What I asked was looking at a feature implemented recently, and how it could be improved. Consumed 3.3 million tokens and create a much better flow.
It had a bug when I started the implementation though related to the API, which I suppose it is something they didn't catch when making their API compatible with CC.
I see that you tried to justify this lower in the thread, but no… it completely invalidates your benchmark. You are not testing the model. You are conflating one specific model host and model performance, and then claiming you are benchmarking the model. All major models are hosted by multiple different services.
In the real world, clients will just retry if there is a server error, and that will not impact response quality at all, and the workflow the model is being used in will not fail. If a workflow is so poorly coded that it doesn’t even have retry logic, then that workflow is doomed no matter which host you use. But again, reliability of the host is separate from the model.
You can make your benchmark valid by having separate leaderboards for model quality and host reliability. I’m not saying to throw the whole thing away. But the current claim is not valid.
And you’re also making an unsourced claim that everyone else has already determined this model sucks? Nah. The first result from Artificial Analysis shows good things: https://x.com/ArtificialAnlys/status/2047547434809880611
But I am still waiting to see the results from the full suite of AA benchmarks.
Why does it matter if the model/architecture/weights are open source or not, given it's their proprietary inference hardware they're currently having issues with? Proprietary or not, the same issue would still be there on their platform.
I hope that DeepSeek wins the AI race or at least gets ahead to the point where it becomes infeasible for bans and regulations against it. It's ridiculous that American legislators are advocating for less regulations for DeepSeek except for their own racist ideas about which AI should be approved or not.
The website now has a link to the announcement on Twitter here https://x.com/deepseek_ai/status/2047516922263285776
Copying text of that below
DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at http://chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
Tech Report: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...
Open Weights: https://huggingface.co/collections/deepseek-ai/deepseek-v4
Gemini-3.1-Pro at 91.0
Opus-4.6 at 89.1
GPT-5.4, Kimi2.6, and DS-V4-Pro tied at 87.5
Pretty impressive
"Due to constraints in high-end compute capacity, the current service capacity for Pro is very limited. After the 950 supernodes are launched at scale in the second half of this year, the price of Pro is expected to be reduced significantly."
So it's going to be even cheaper
Have you noticed the deepseek-v4-pro performing worse than deepseek-v4-flash? It performed even worse than qwen3.5-27b. I found it surprising and I'm wondering if there is a bug on my software because I had to implement sending the `reasoning_content` otherwise the API failed with BadRequestError.
It's five times bigger in both total and active parameters!
https://api-docs.deepseek.com/guides/coding_agents#integrate...
Stuff that was prohibitive six months ago is now up for grabs. We keep on working on the infra level now, swithcing models whenever we run out of credits, or want a different result. The question is how do we build context, architecture and ensure the agent is effective and efficient..... wouldn't it be good if we simply used less energy to make these AI calls?
bash({"command":"gh pr create --title "Improve Calendar module docs and clean up idiomatic Elixir" --body "$(cat <<'EOF'
Problem
The Calendar modu...
dang, probably the two should be merged and that be the link
Where previously I was wary to under-provide the intelligence level, I'm now more excited about the idea of being able to give these pretty large intelligent models to my application. The idea that for basically sub-agents, we can fine-tune them, should reasonably expect to perform as well as Opus for a specific subtask of which my applications have many.
In other words, we can run a general-purpose intelligent model, Sonnet or Opus, orchestrating a fleet of, let's say, 30 to 50 of these sub-agents that have been fine-tuned. By doing that, I can get very low pricing versus something that would have occurred if I used Opus or Sonnet for everything.
Kimi 2.6 went hard and left me with a buggy mess. GLM 5.1 hedged and made a 25 line change (but it was an improvement). DS V4 went hard, fixed its issues along the way, and left me with a significantly nicer codebase! (...that I will now be spending some time testing before releasing to the project)
[0]: lmcli (simple, Go, nice UX, MIT licensed, works well with DS V4) https://codeberg.org/mlow/lmcli
Which strikes me as odd - Inwoukd have assumed someone had an edge in terms of at least 10% extra GPUs.
Are there comparisons between Pro non thinking and Flash thinking ? i don't really get the use case for Flash thinking and Pro non thinking
Keep an eye on https://huggingface.co/unsloth/models
Update ten minutes later: https://huggingface.co/unsloth/DeepSeek-V4-Pro just appeared but doesn't have files in yet, so they are clearly awake and pushing updates.
I have never tried one yet but I am considering trying that for a medium sized model.
[0]: https://aibenchy.com/compare/deepseek-deepseek-v4-flash-high...
"Not seduced by praise, not terrified by slander; following the Way in one's conduct, and rectifying oneself with dignity." (不诱于誉,不恐于诽,率道而行,端然正己)
(It is mainly used to express the way a Confucian gentleman conducts himself in the world. It reminds me of an interview I once watched with an American politician, who said that, at its core, China is still governed through a Confucian meritocratic elite system. It seems some things have never really changed.
In some respects, Liang Wenfeng can be compared to Linux. The political parallel here is that the advantages of rational authoritarianism are often overlooked because of the constraints imposed by modern democratic systems. )
Strix halo has 256 GB/s bandwidth for $2500. The Flash model has 13 GB activations.
256 / 13 = 19.6 tokens per second
Except you cannot fit it into the maximum RAM of 128 GB Strix Halo supports. So move on.
Another option is Threadripper. That's 8 memory channels. Using older DDR4-3200 you get roughly 200 GB/s. For $2000.
200 / 13 = 15.4 tokens per second
But, a chunk of per-token weights is actually always the same and not MoE, so you would offload that to a GPU and get a decent speedup. Say 25 tokens per second total.
Then likely some expensive Mac. No idea.
Eventually you arrive at a mining rig chassis with a beefy board and multiple GPUs. That has the benefit of pipelining. You run part of the model on one GPU and move on, so another batch can start on the first one. Low (say 30-100) tps individually, but a lot more in parallel. Best get it with other people.
A mac with 256 GB memory would run it but be very slow, and so would be a 256GB ram + cheapo GPU desktop, unless you leave it running overnight.
The big model? Forget it, not this decade. You can theoretically load from SSD but waiting for the reply will be a religious experience.
Realistically the biggest models you can run on local-as-in-worth-buying-as-a-person hardware are between 120B and 200B, depending on how far you’re willing to go on quantization. Even this is fairly expensive, and that’s before RAM went to the moon.
The flash version here is 284B A13B, so it might perform OK with a fairly small amount of VRAM for the active params and all regular ram for the other params, but I’d have to see benchmarks. If it turns out that works alright, an eBay server plus a 3090 might be the bang-for-buck champ for about $2.5K (assuming you’re starting from zero).
Codex shows ~258k for me and Claude Code often shows ~200k, so I’m curious how DeepSeek is exposing such a large window.
The 1M window might be usable, but it will probably underperform against a smaller window of course.
It's trendy to say the US govt is now authorization, but that's just pure naïve groupthink.
is this not cool tech, available for use?
i look forward to seeing what gets made on top of deepseek 4, more than what it means for US politics.
especially with how open deepseek is with its advancements, im excited to see how they get applied into sota western models
But if it does, then in the following week we'll see DeepSeek4 floods every AI-related online space. Thousands of posts swearing how it's better than the latest models OpenAI/Anthropic/Google have but only costs pennies.
Then a few weeks later it'll be forgotten by most.
{kind=link}